") Nvidia的Ada Lovelace架構(gòu)深度解讀!
Nvidia的Ada Lovelace架構(gòu)深度解讀!
Nvidia 的 RTX 4090 采用 Nvidia 的最新架構(gòu),以早期計算先驅(qū)Ada Lovelace的名字命名。與之前的架構(gòu) Ampere 相比,Ada Lovelace 享有制程節(jié)點優(yōu)勢,使用臺積電為 GPU 定制的 4 納米制程。Nvidia 還強(qiáng)調(diào)了光線追蹤性能,以及旨在彌補(bǔ)啟用光線追蹤對性能造成的巨大影響的技術(shù)。但光線追蹤性能并不是唯一重要的事情,因為有很多游戲根本不支持光線追蹤。此外,大多數(shù)使用光線追蹤的游戲僅使用它來渲染某些效果;傳統(tǒng)的光柵化仍然負(fù)責(zé)渲染大部分場景。
我還覺得對光線追蹤的關(guān)注掩蓋了 Nvidia 工程師為提高其他領(lǐng)域的性能所做的工作。在本文中,我們將使用一組正在進(jìn)行的微基準(zhǔn)測試來研究 Nvidia 的 Ada Lovelace 架構(gòu)。我們將關(guān)注影響各種工作負(fù)載性能的領(lǐng)域,無論是否有光線追蹤,特別強(qiáng)調(diào)緩存和內(nèi)存子系統(tǒng)。
特別感謝Skyjuice在 RTX 4090 上運行測試。
GPU 概覽
SM 或流式多處理器構(gòu)成了 Nvidia GPU 的基本構(gòu)建塊。它們與 AMD 的 RDNA 和 RDNA 2 架構(gòu)上的 WGP 或工作組處理器大致相當(dāng)。SM 和 WGP 都具有 128 個 FP32 通道(或著色器,如果您愿意的話),并進(jìn)一步分為四個塊,每個塊有 32 個通道。Ampere 最大的客戶端芯片 GA102 已經(jīng)非常龐大。
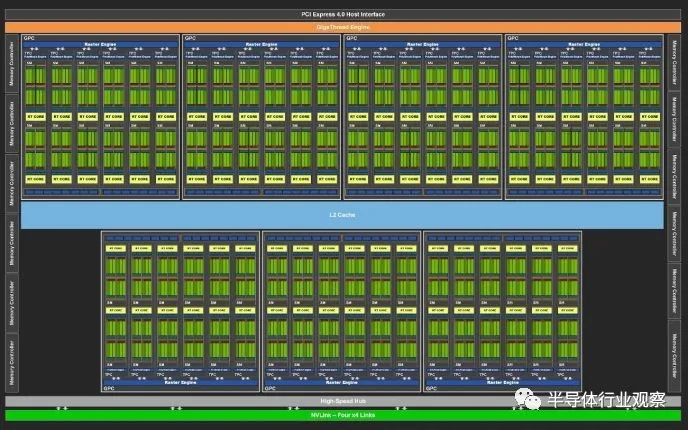
GA102 框圖,來自 Nvidia 的白皮書 Ada Lovelace 表面上與 Ampere 相似,每個 SM 具有相似的計算特性。然而,它已經(jīng)通過roof擴(kuò)大了規(guī)模。AD102 有 144 個 SM,而 GA102 有 84 個,代表 SM 數(shù)量增加了 71%。RTX 4090 僅啟用了 128 個 SM,但這仍然代表了 52% 的增長。將其與較大的時鐘速度提升相結(jié)合,我們正在研究計算能力的巨大飛躍。
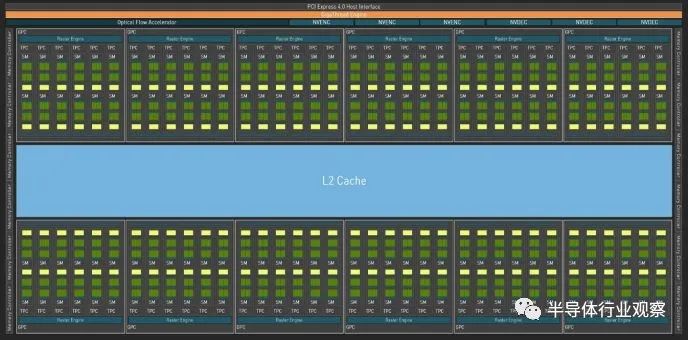
AD102 框圖,來自 Nvidia 的白皮書 但擴(kuò)大 GPU 的規(guī)模不僅僅是復(fù)制和粘貼工作。GPU 往往需要來自內(nèi)存子系統(tǒng)的大量帶寬,所有這些額外的 SM 都必須以某種方式提供。讓我們轉(zhuǎn)向我們正在進(jìn)行的微基準(zhǔn)測試,看看 Ada Lovelace 的內(nèi)存層次結(jié)構(gòu)。
緩存和內(nèi)存延遲
我們正在啟動緩存和內(nèi)存延遲基準(zhǔn)測試,因為這將使我們對緩存設(shè)置有一個很好的了解。 與 Ampere 一樣,Ada Lovelace 堅持使用經(jīng)過驗證的真正的兩級緩存方案。Nvidia 最近的兩種架構(gòu)都為每個 SM 提供了一個大型 L1 緩存,但 Ada Lovelace 大大擴(kuò)展了 L2 緩存。Ampere 具有傳統(tǒng)大小的 6 MB L2,但 AD102 包含 96 MB L2。RTX 4090 啟用了 72 MB 的二級緩存。從 Ampere 到 Ada Lovelace,Nvidia 沒有享受到顯著的 VRAM 帶寬增加,因此 Ada 的 L2 獲得了巨大的容量提升,以防止隨著計算容量的擴(kuò)大而出現(xiàn)內(nèi)存帶寬瓶頸。 AMD 的 RDNA 2 架構(gòu)選擇了復(fù)雜的四級緩存系統(tǒng),具有三級共享緩存。每個著色器陣列中有一個 128 KB 的 L1 來吸收來自相對較小 (16KB) 的 L0 緩存的緩存未命中流量。L2 的作用可與 Ampere 的 L2 相媲美,而大型 Infinity Cache 可幫助 AMD 通過更便宜(且功耗更低)的 VRAM 子系統(tǒng)實現(xiàn)高性能。
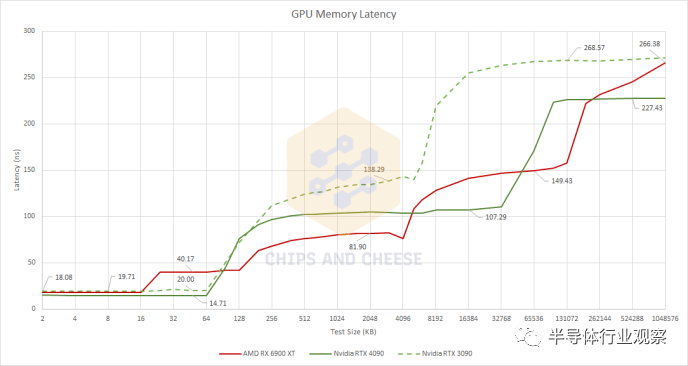
有趣的是,英特爾的 A770 的 L2 延遲與 RTX 4090 相似 Ada Lovelace 的緩存子系統(tǒng)具有令人印象深刻的延遲特性。第一級 SM 私有緩存看起來與 Ampere 的相似,但 Ada Lovelace 的更高時鐘速度使其具有整體延遲優(yōu)勢。但 L2 是樂趣的開始。盡管容量比 Ampere 的 L2 增加了 12 倍,但 Nvidia 還是設(shè)法將延遲降低了大約 30 ns。Ampere 的 L2 在延遲方面接近 AMD 的 Infinity Cache,但 Ada Lovelace 的 L2 現(xiàn)在在容量和延遲方面位于 RDNA2 的 L2 和 Infinity Cache 之間。 與 Ampere 相比,RDNA 2 的緩存子系統(tǒng)看起來很有競爭力。這兩個交易在小測試規(guī)模上受到打擊,而 AMD 在 L2 規(guī)模及以上區(qū)域具有明顯優(yōu)勢。Ada Lovelace 改變了這一點,隨著測試規(guī)模從 AMD 的 L2 溢出,Nvidia 現(xiàn)在享有明顯的優(yōu)勢。Ada Lovelace 的內(nèi)存延遲也有所下降,盡管這在很大程度上可能是由于更好的 L2 性能,因為必須在通往內(nèi)存的路上檢查 L2。 隨著 Ada Lovelace 改進(jìn) L2,AMD 發(fā)現(xiàn)自己處于一個不舒服的位置,Nvidia 使用單級緩存來填補(bǔ) AMD 的 L2 和 Infinity Cache 的角色。更少的緩存級別意味著更低的復(fù)雜性,以及更少的潛在標(biāo)簽和每次內(nèi)存訪問的狀態(tài)檢查。當(dāng)然,更多的緩存級別意味著在容量、延遲和帶寬權(quán)衡方面具有更大的靈活性。RDNA 2 與 Ampere 相比無疑證明了這一點,它具有更快的 L2 緩存和更大的 Infinity Cache,幾乎與 Ampere 的 L2 一樣快。但艾達(dá)洛夫萊斯是一個不同的故事。
帶寬
延遲是影響 GPU 性能的一個因素,但帶寬也是一個因素,而且 GPU 往往比 CPU 更需要帶寬。首先,我們將使用單個 OpenCL 工作組測試帶寬。屬于同一工作組的線程能夠共享本地內(nèi)存,這意味著它們將被限制在單個 WGP 或 SM 上運行。這是我們可以得到的最接近 GPU 單核帶寬測試的結(jié)果。
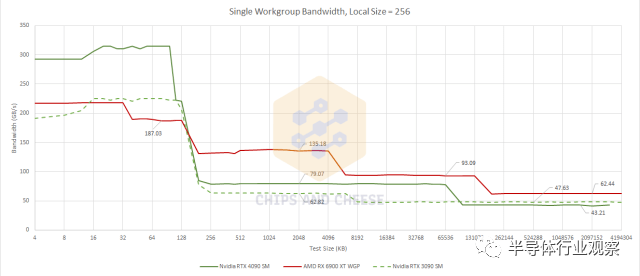
一旦我們進(jìn)入 L2 及更高級別,RDNA 2 WGP 就比 Ampere SM 享有良好的帶寬優(yōu)勢。Ada Lovelace 并沒有改變這一點,但 L2 帶寬確實比 Ampere 有所提高。再次,我們看到 Nvidia 的工程師在 L2 上做得非常出色。在 AMD 方面,我們開始看到 RDNA 2 非常擅長處理低占用工作負(fù)載的跡象。讓我們增加工作組數(shù)量來測試擴(kuò)展,看看這種優(yōu)勢能持續(xù)多久。
帶寬擴(kuò)展
共享緩存設(shè)計很難,尤其是在 GPU 中,因為緩存必須連接到大量客戶端并滿足它們的帶寬需求。在這里,我們正在使用越來越多的工作組來測試帶寬。和以前一樣,每個工作組都必須使用單個 WGP 或 SM,因此我們看到共享緩存可以應(yīng)對更多 WGP 和 SM 發(fā)揮作用并開始要求帶寬的能力。 Ada Lovelace 是對 Ampere 的明顯改進(jìn),并且在匹配的工作組數(shù)量下實現(xiàn)了更高的帶寬。使用 RTX 4090 的所有 SM 時,我們看到了驚人的 5 TB/s 帶寬——幾乎是使用 RTX 3090 的 84 個 SM 時看到的兩倍。Nvidia 成功地擴(kuò)大了 L2 容量,同時也擴(kuò)大了帶寬以支持大量 SM,這是一項了不起的成就。Ada Lovelace 在低入住率的情況下超越 Ampere 的能力是錦上添花。
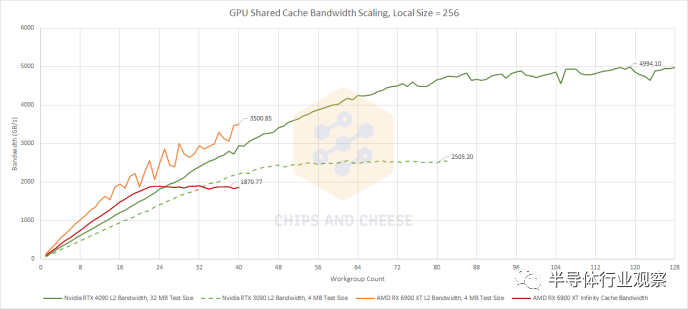
AMD 在小型工作負(fù)載方面仍然具有優(yōu)勢。RDNA 2 的 L2 在擴(kuò)展方面尤其令人印象深刻,可以處理 40 個 WGP,要求最大帶寬,而不會出現(xiàn)爭用問題。大型 Infinity Cache 也表現(xiàn)不錯,在low occupancy.的情況下?lián)魯×?Ampere 和 Ada Lovelace。但與我們在英特爾的 Arc A770 上看到的不同,英偉達(dá)也不甘落后。 更重要的是,Ada Lovelace 在低占用率下的性能提升意味著 RDNA 2 失去優(yōu)勢的速度比對抗 Ampere 的速度更快。由于有超過 24 個工作組在運行,Ada Lovelace 的 SM 可以從 L2 提取比 RDNA 2 的 WGP 從 Infinity Cache 獲得的更多帶寬。RDNA 2 的 L2 帶寬優(yōu)勢一直持續(xù)到 Nvidia 擁有超過 50 個 SM。但是 RDNA 2 和 Ada Lovelace 之間的 L2 比較就不那么簡單了,因為 L2 容量不再像 RDNA 2 和 Ampere 那樣處于同一個范圍內(nèi)。在高入住率下,Ampere 比 RDNA 2 具有相當(dāng)大的優(yōu)勢,但 Ada Lovelace 更進(jìn)一步。RDNA 2 的 L2 和 Infinity Cache 與 Lovelace 的 L2 相比都處于明顯劣勢。 接下來,讓我們看看當(dāng)測試大小大到足以溢出緩存時會發(fā)生什么。
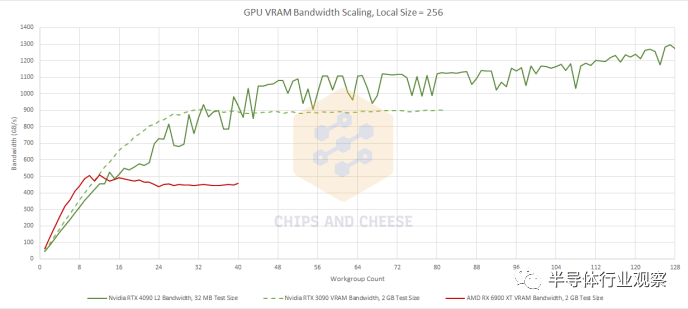
我們測量的 RTX 4090 在高占用率下的理論帶寬高于理論帶寬,這可能是因為一些重復(fù)讀取被合并并廣播到多個 SM。我有沒有提到 GPU 測試很難? Ada Lovelace 的擴(kuò)展速度不如 Ampere,但這種優(yōu)勢并不是特別重要,因為 Ada Lovelace 應(yīng)該為 L2 之外的更多內(nèi)存訪問提供服務(wù)。VRAM 帶寬也沒有比 Ampere 顯著增加,但兩張 Nvidia 卡的絕對帶寬仍然很大。從角度來看,它們的理論顯存帶寬幾乎與 AMD 的 Radeon VII 一樣多,后者具有基于 HBM2 的顯存子系統(tǒng)。 AMD 的 RDNA 2 在低占用率下再次享有帶寬優(yōu)勢,但 Nvidia 最近的架構(gòu)為大型工作負(fù)載提供了更多的 VRAM 帶寬。AMD 也更依賴于他們的 Infinity Cache,因為他們的 VRAM 帶寬在加載十幾個 WGP 后停止擴(kuò)展。 最后,讓我們測試 512 個工作組在高占用率下的帶寬。這應(yīng)該讓每個 SM 或 WGP 有多個工作組可供使用,每個工作組中都有大量的并行性。
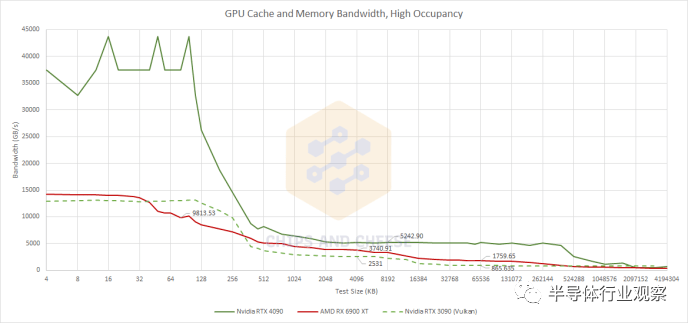
使用Nemes的基于 Vulkan 的帶寬測試獲得的 RTX 3090 結(jié)果。與此處的 OpenCL 結(jié)果不直接可比較,但無論如何都提供了上下文 由于 RTX 4090 的高時鐘速度和瘋狂的 SM 數(shù)量,Ada Lovelace 的 L1 帶寬突破了roof并破壞了該圖表上的比例。L2 緩存帶寬也不是開玩笑的,它比 Ampere 的帶寬有了很大的改進(jìn)。即使 RDNA 2 可以為 L2 或 Infinity Cache 的內(nèi)存訪問提供服務(wù),RDNA 2 也難以與之競爭。AMD 確實為他們完成了工作。
本地內(nèi)存延遲
在 GPU 上,本地內(nèi)存是一小塊暫存器內(nèi)存,由工作組中的所有線程共享,并且在工作組之外無法訪問。軟件必須明確地將數(shù)據(jù)加載到本地內(nèi)存中,一旦工作組完成執(zhí)行,本地內(nèi)存內(nèi)容就會消失。這使得本地內(nèi)存更難使用,但作為交換,本地內(nèi)存通常比普通的全局內(nèi)存子系統(tǒng)提供更快和更一致的性能。本地內(nèi)存的一種用途是在光線追蹤時存儲 BVH 遍歷堆棧。 Nvidia 將本地內(nèi)存稱為“共享內(nèi)存”,而 AMD 將其稱為“本地數(shù)據(jù)共享”或 LDS。
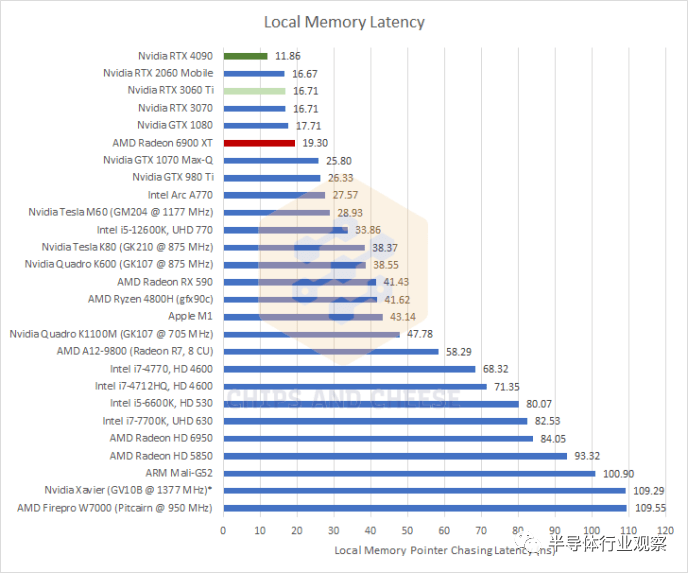
*由于時鐘斜坡非常緩慢,Nvidia Xavier 的測量可能不準(zhǔn)確 與 Ampere 相比,Ada Lovelace 在本地內(nèi)存延遲方面提供了不錯的改進(jìn),從而擴(kuò)大了 Nvidia 在 RDNA 2 上的領(lǐng)先優(yōu)勢。這里需要注意的是,Nvidia 的兩種架構(gòu)都使用單個 128 KB 的 SRAM 塊作為 L1 緩存和本地內(nèi)存。該架構(gòu)可以通過改變標(biāo)記 SRAM 的數(shù)量來提供 L1 高速緩存和本地內(nèi)存大小的不同組合。相比之下,AMD 為每個 CU(WGP 的一半)使用 16 KB 的專用 L0 矢量緩存,以及 128 KB 的專用本地內(nèi)存。這意味著 Nvidia 在實踐中將擁有更少的本地內(nèi)存容量。
計算
試圖確定每個周期、每個 WGP 的吞吐量數(shù)據(jù)是一種令人沮喪的練習(xí),因為很難確定 GPU 運行的時鐘速度。我們還需要調(diào)查 Nvidia 的 Ampere 和 Ada Lovelace 架構(gòu)是否在我們的指令速率測試中做了一些奇怪的事情,這很難,因為我也不擁有。 至少據(jù)我們所知,Ada Lovelace 的表現(xiàn)很像 Ampere。常見 FP32 操作(如加法和融合乘法加法)的延遲保持在 4 個周期。用于比較的 RDNA 2 對這些操作有 5 個周期延遲。 總結(jié)各種操作的吞吐量特征:
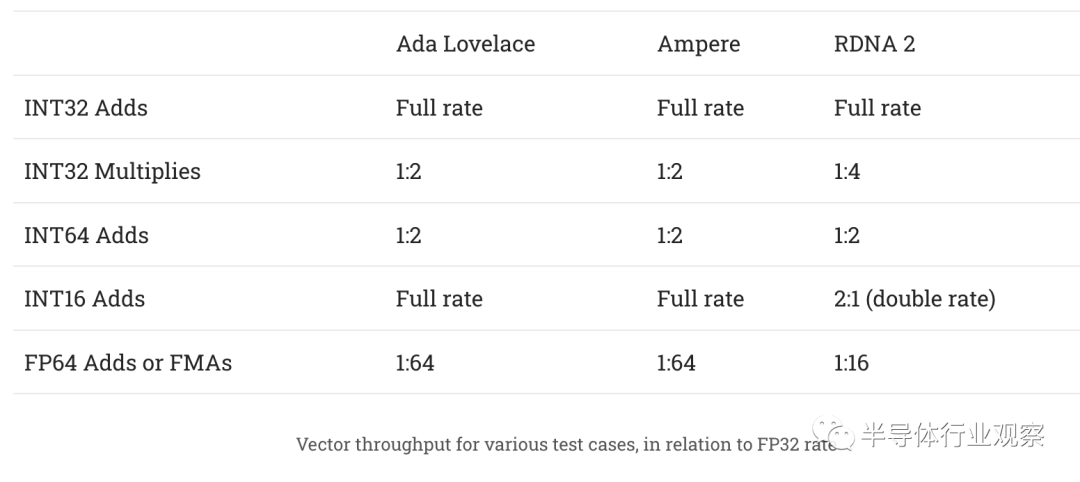
RDNA 2 還以雙倍速率執(zhí)行 FP16 操作。根據(jù) Ada 白皮書,Ampere 和 Ada Lovelace 可以以 1:1 的速率執(zhí)行 FP16,但我們無法驗證這一點,因為 Nvidia 卡都不支持 OpenCL 的 FP16 擴(kuò)展。
Atomics延遲
與 CPU 非常相似,現(xiàn)代 GPU 支持原子操作以允許線程之間的同步。OpenCL 通過 atomic_cmpxchg 內(nèi)在函數(shù)公開這些原子操作。這是我們可以在 GPU 上進(jìn)行的最接近內(nèi)核到內(nèi)核延遲測試的方法。跟游戲有關(guān)系嗎?可能不會,因為我從未見過在游戲著色器代碼中使用這些指令。但是測試有趣嗎?是的。 與 CPU 不同,GPU 具有不同的atomic指令來處理本地和全局內(nèi)存。本地內(nèi)存(共享內(nèi)存或 LDS)上的原子應(yīng)該完全包含在 SM 或 WGP 中,因此應(yīng)該比全局內(nèi)存上的原子快得多。如果我們想稍微擴(kuò)展一下,本地內(nèi)存上的原子延遲大致相當(dāng)于測量 CPU 內(nèi)核上兄弟 SMT 線程之間的內(nèi)核到內(nèi)核延遲。
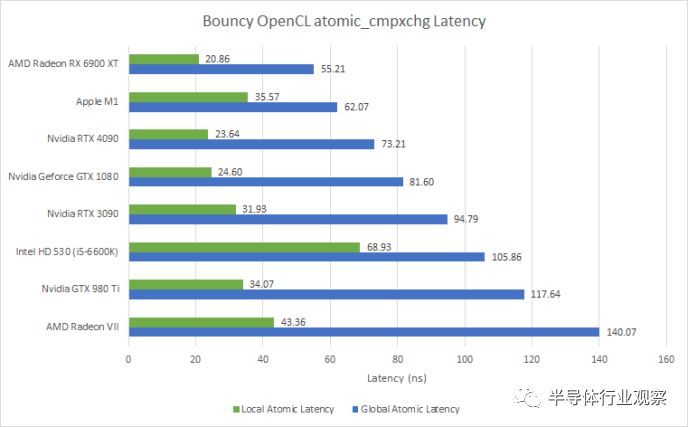
Ada Lovelace 在這里提供了對 Ampere 的增量改進(jìn),這在很大程度上可能是由于更高的時鐘速度。AMD 的 RDNA 2 在這項測試中表現(xiàn)非常出色。從絕對意義上說,有趣的是 GPU 上的“核心到核心”延遲如何與 Ryzen CPU 上的跨 CCX 訪問相媲美。
最后的話
審核編輯 :李倩
-
處理器
+關(guān)注
關(guān)注
68文章
19409瀏覽量
231190 -
gpu
+關(guān)注
關(guān)注
28文章
4776瀏覽量
129358 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3848瀏覽量
91979
原文標(biāo)題:英偉達(dá)最新GPU架構(gòu),深度解讀!
文章出處:【微信號:芯長征科技,微信公眾號:芯長征科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
0xmd公司通過NVIDIA GPU打造醫(yī)療AI解決方案
MediaTek與NVIDIA攜手打造超級芯片
MediaTek與NVIDIA攜手打造GB10 Grace Blackwell超級芯片
聯(lián)發(fā)科與NVIDIA合作 為NVIDIA 個人AI超級計算機(jī)設(shè)計NVIDIA GB10超級芯片
4G模組加解密藝術(shù):通用函數(shù)的深度解讀

嵌入式MXM模塊(NVIDIA安培架構(gòu))
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級芯片
NVIDIA推出兩款基于NVIDIA Ampere架構(gòu)的全新臺式機(jī)GPU
RTX 5880 Ada Generation GPU與RTX? A6000 GPU對比

NVIDIA發(fā)布兩款新的專業(yè)顯卡RTX A1000、RTX A400

Nvidia AI芯片GPU架構(gòu)路線圖分析與解讀
任天堂Switch 2游戲機(jī)預(yù)計明年首季推出,采用英偉達(dá)Tegra T23芯片
深度解讀Nvidia AI芯片路線圖

NVIDIA的Maxwell GPU架構(gòu)功耗不可思議






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論