 介紹一種信息抽取的大一統方法USM
介紹一種信息抽取的大一統方法USM
一句話總結
信息抽取任務具有多樣的抽取目標和異構的結構,而傳統的模型需要針對特定的任務進行任務設計和標簽標注,這樣非常的耗時耗力。本文提出一種USM方法,將各種信息抽取任務通過一種統一的模型方法完成。
USM
信息抽取(IE)的挑戰在于標簽模式的多樣性和結構的異構性。
傳統方法需要針對特定任務的模型設計,并且嚴重依賴昂貴的監督,因此很難推廣到新模式。
在本文中,我們將 IE 分解為兩種基本能力,「結構化」(Structuring)和「概念化」(Conceptualizing),它們由不同的任務和模式共享。
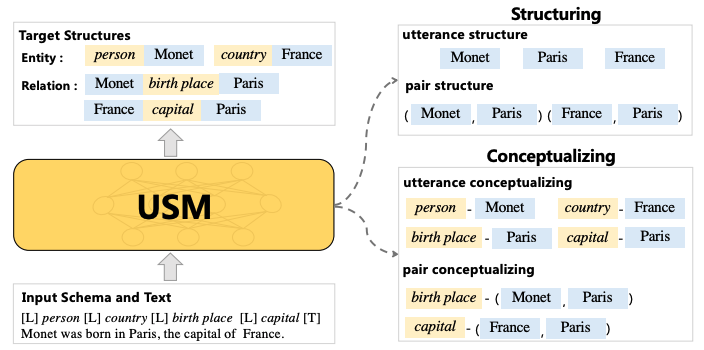
基于這種范式,我們建議使用「統一語義匹配 (Unified Semantic Matching, USM)」 框架對各種 IE 任務進行通用建模,該框架引入了三個統一的標記鏈接操作來建模結構化和概念化的能力。
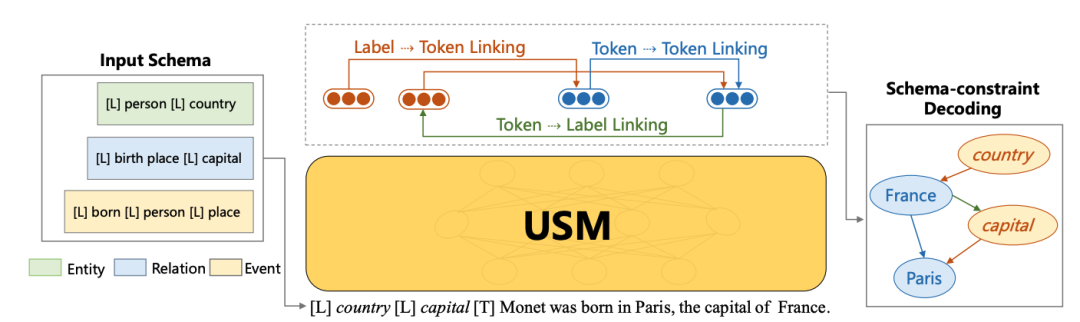
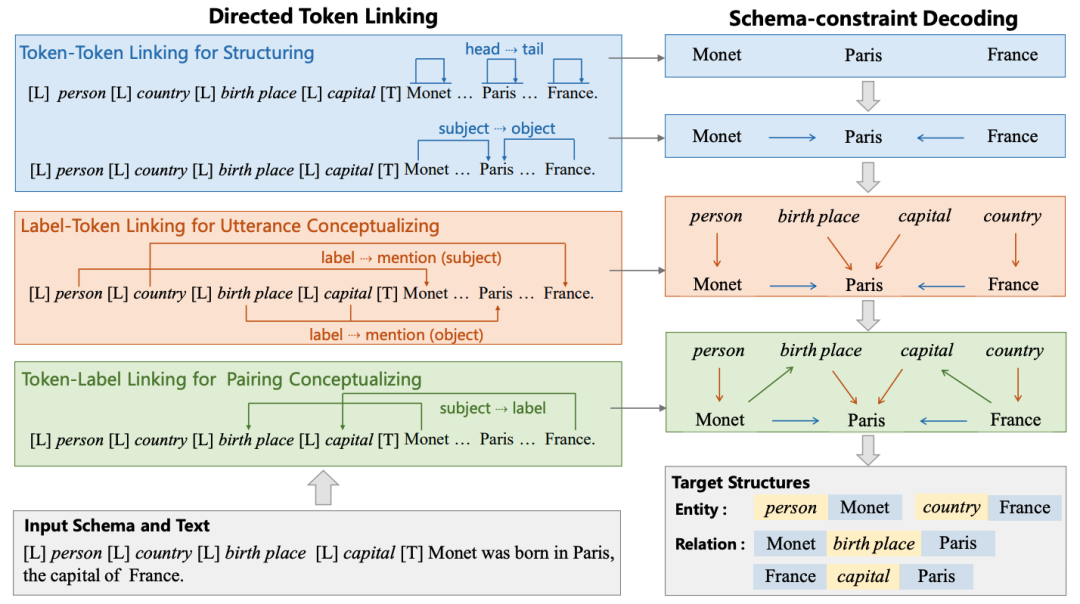
這樣,USM 可以聯合編碼模式和輸入文本,并行地統一提取子結構,并按需可控地解碼目標結構。
本文的貢獻為:
算法細節



實驗分析
對 4 個 IE 任務的實證評估表明,所提出的方法在監督實驗下實現了最先進的性能,并在零/少鏡頭傳輸設置中表現出強大的泛化能力。
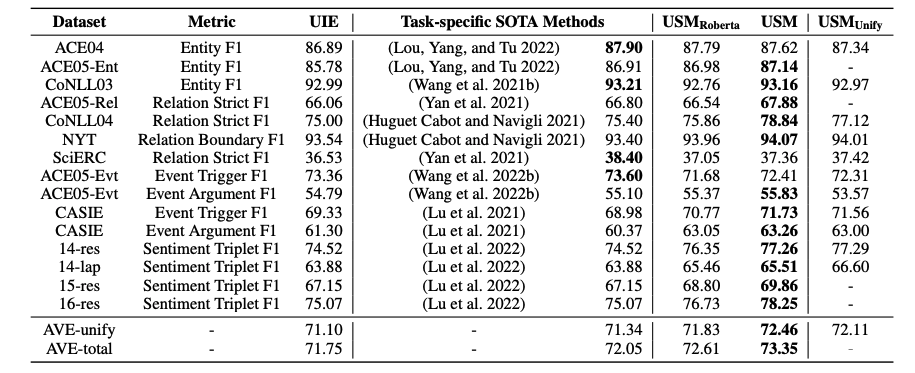
USM在不同數據集上的結果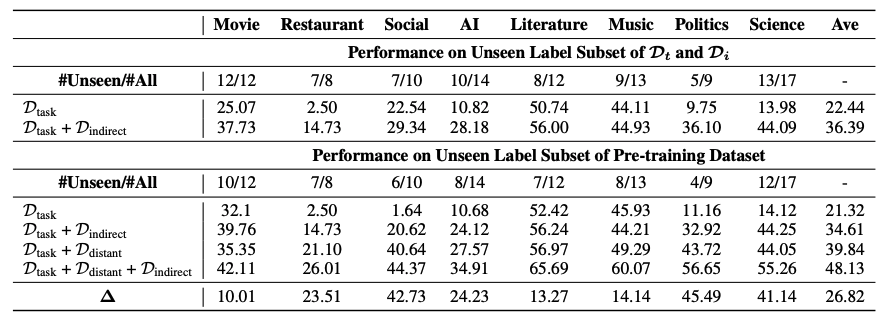
零樣本遷移實驗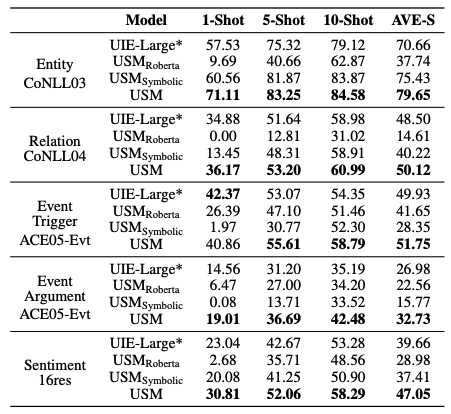
少樣本實驗
總結
在本文中,我們提出了一個統一的語義匹配框架——USM,它對提取模式和輸入文本進行聯合編碼,并行地統一提取子結構,并按需可控地解碼目標結構。
實驗結果表明,USM 在監督實驗下實現了最先進的性能,并在零/少場景設置下表現出強大的泛化能力,驗證了 USM 是一種新穎、可傳輸、可控和高效的框架。
對于未來的工作,我們希望將 USM 擴展到 NLU 任務,例如文本分類,并研究 IE 的更多間接監督信號,例如文本蘊含。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3669瀏覽量
135247 -
編解碼
+關注
關注
1文章
140瀏覽量
19662 -
USM
+關注
關注
0文章
7瀏覽量
7245
原文標題:AAAI2023 | 百度+中科院提出USM:一種信息抽取的大一統方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PD快充協議有望一統嗎?
文本分類中一種混合型特征降維方法
快遞好壞京東一人說了算,天天快遞服務太爛?躺著被“封殺”
基于WebHarvest的健康領域Web信息抽取方法
蘋果實現大一統:打通PC、平板、手機隔閡
為應對蘋果大一統,微軟盡力讓win10全力擁抱Android
華為要最終實現其全場景、大一統的生態
一種面向維吾爾語的停用詞抽取方法
一種全新易用的基于Word-Word關系的NER統一模型
基于統一語義匹配的通用信息抽取框架USM
學技術 | 充電器大一統:USB Type-C接口PD協議解決方案






 工商網監
工商網監
評論