 Machine Outliner簡介
Machine Outliner簡介
Machine Outliner簡介
在嵌入式領域,代碼體積(code size)優化能夠減少內存的使用,對產品的競爭力至關重要。對當代產品而言, code size優化可以為產品放入更多特性,增強競爭力;對下一代產品而言,code size優化能夠帶來產品功耗和成本的競爭力提升 ^[1]^ 。LLVM Machine Outliner是一種編譯器優化技術,可以識別重復代碼片段,將其提取出來并轉換成一個獨立的函數,從而降低程序code size。
示例
通過以下代碼示例,描述是否開啟Machine Outliner優化的效果:
int div(int x) {
int a = x / 2;
int b = x;
return b / a;
}
int sub(int x) {
int a = x / 2;
int b = x;
return b - a;
}
以上代碼片段由div和sub兩個函數組成,通過函數參數x,對變量a和b賦值,然后分別返回b和a相除,以及b和a相減的結果。其中,關于變量a、b賦值部分為重復代碼片段。
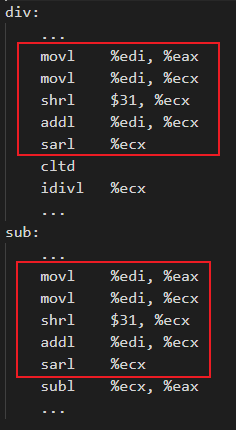
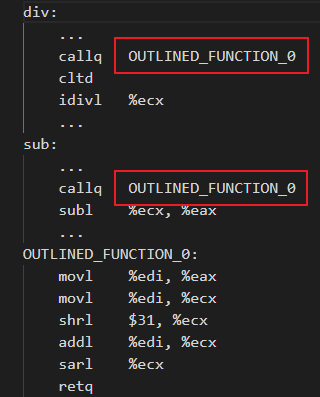
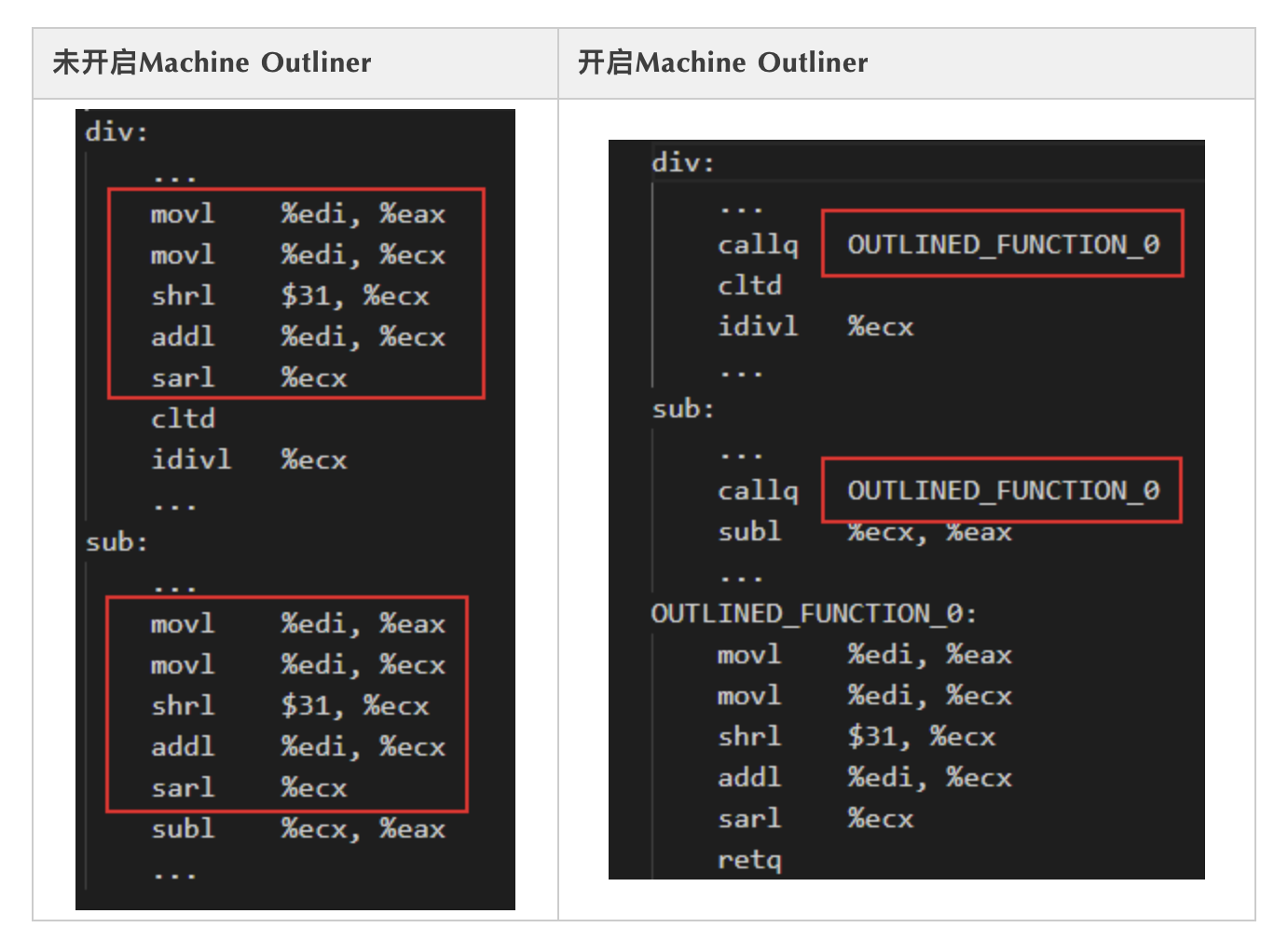
是否開啟Machine Outliner優化,在匯編層面的區別如下表所示:
| 未開啟Machine Outliner
| 開啟Machine Outliner
 |
|
如果不開啟Machine Outliner優化,則會分別在標簽div和sub下生成相關的重復匯編指令。開啟Machine Outliner優化,則會將重復指令提取為單獨的函數,并且在重復指令初始位置添加函數調用,從而降低程序code size。在編譯階段,可以通過使用 -mllvm -enable-machine-outliner=always 選項開啟Machine Outliner優化,提取出的函數統一以“OUTLINED_FUNCTION_n”的形式命名。
后綴樹
Machine Outliner優化依靠后綴樹(Suffix Tree)的形式進行重復指令序列的識別,后綴樹的構造和重復字符串查詢操作均可在線性時間復雜度內完成,從而實現了Machine Outliner優化的效率提升。
后綴樹是一種將字符串所有后綴存儲在一棵樹中的數據結構,目的是用來支持快速搜索和大量字符串匹配和查詢,能高效解決很多關于字符串的問題 ^[2]^ 。字符串S對應的后綴樹,也就是由該字符串所有后綴所共同構成的壓縮字典樹。
字典樹(Trie)是一種樹形數據結構,其中每條邊用來表示一個字符,且每個節點出邊對應的字符都不相同,將根節點到某一節點路徑上所經過的字符拼接起來,即為該節點所表示的字符串。壓縮字典樹(Compressed Trie)由字典樹演變而來,將字典樹中的單節點鏈條壓縮為一個節點,即將相鄰的具有相同前綴的節點合并,可得到對應的壓縮字典樹。字符串“ABD$0”對應的字典樹和壓縮字典樹如下所示:

后綴樹的構建需要經過字符串后綴生成和壓縮字典樹構建兩步:
1 生成字符串S的所有后綴,以“ABCAB$0”(“$0”是結束字符)為例,該字符串的所有后綴為:
ABCAB$0
BCAB$0
CAB$0
AB$0
B$0
$0
2 為以上所有后綴生成字典樹,并且合并節點生成相應的壓縮字典樹:
字典樹
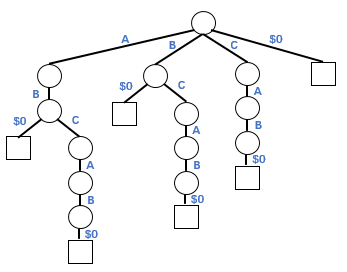
壓縮字典樹
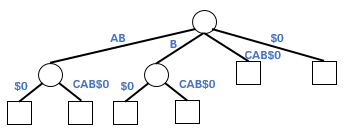
令字符串S的長度為n,通過構建字符串S所對應的后綴樹,即可在O(n)時間復雜度內,完成字符串重復次數,以及重復字符串長度的檢索 。
重復次數搜索: 假設字符串T在字符串S中重復次數為m,則字符串S應有m個后綴以字符串T為前綴,即字符串T所對應節點的葉節點數量為其重復次數。
重復字符串長度搜索: 由于重復字符串出現次數大于1,所以字符串T在后綴樹中一定以非葉節點的形式表示,字符串T的長度為該非葉節點到根節點所經過的字符總數。
編譯器實現
LLVM對于Machine Outliner的實現在寄存器分配之后,主要集中在MachineOutliner.cpp中,基于機器指令表示(MIR)進行函數的分析和提取,以實現程序code size優化。
編譯器側的實現過程可劃分為指令映射、后綴樹構建和函數提取三個階段:
1 將指令映射成特定的無符號數,并以指令-無符號數對的形式存儲在Map中;
2 以無符號數組為輸入構建指令序列對應的后綴樹,并且找出所有長度大于2的重復指令序列;
3 遍歷后綴樹并進行收益計算,從而得到包含正收益序列的候選列表,對于具備收益的候選項進行函數外提。
指令映射
首先需要遍歷源文件對應的所有指令,將所有合法指令映射為無符號數(InstrNumber),并以指令-無符號數對的形式存儲在Map中,如果兩條指令的操作碼和操作數均相同,則認為兩條指令相同。對于所訪問的每條指令,首先應該在Map中查詢是否已經存儲了相同的指令,如果是,則返回對應的InstrNumber;否則,將該指令插入到Map中,InstrNumber自加。
至此,所有指令均以無符號數的形式進行唯一標識,以作為構建后綴樹的輸入。而對于讀寫棧指針、PC相關,以及其他與call、ret指令有數據依賴的指令,將被判定為非法指令,為保證程序運行的正確性,這些指令不參與上述映射過程。

后綴樹構建
假定將無符號數以字符形式表示,以指令映射輸出的無符號數組為輸入,通過添加終結符和構建后綴樹,即可在線性時間復雜度內,完成字符串S的所有重復子字符串長度、重復次數和起始下標的計算,這些重復字符串將以候選列表的形式輸出。
以第2節所示匯編指令為例,經過指令映射和添加終結符后可得到字符串S:
ABCDEFG$0ABCDEH$1`,其中添加終結符可避免跨函數指令序列提取。

以字符串S為輸入,構建后綴樹:

令ABCDE所指向的節點為P,單個字符所表示的距離為1,則節點P到根節點的距離為5,大于其他非葉節點到根節點的距離,因此ABCDE為字符串S中的最長重復子字符串T。節點P有兩個子節點,因此字符串T的重復次數為2,且T在S中的起始下標分別為[0,4],[8,12]。
函數提取
完成后綴樹構建和重復字符串解析后,還需要對提取該重復字符串對應的指令序列進行code size收益計算,計算公式如下:
codesize_benefit = codesize_before - codesize_after
codesize_before = 指令序列重復次數 * 指令序列codesize
codesize_after = 插入call指令的codesize + 指令序列codesize + 插入ret指令的codesize
如果收益大于1,則提取同一重復字符串對應的所有指令序列,以構造outline函數,并在函數末尾額外添加ret指令。而對于重復字符串指向的下標位置,需要刪除初始指令序列,并且通過call指令增加對outline函數的調用。

總結
本文對Machine Outliner的基本概念和實現方法進行了簡單介紹,通過將所有指令映射成為無符號數,并且以后綴樹的形式對重復指令序列進行高效識別,最后提取具有正收益的指令序列作為outline函數,實現程序code size優化,從而提高代碼的可讀性并且減少程序的內存占用。
在源碼中大量使用宏、模板,以及循環展開的場景下,開啟Machine Outliner優化將會獲得明顯的code size收益;而對于程序本身code size很小、結構化設計良好,或者包含大量違反外提約束的情況,Machine Outliner對code size的優化效果不顯著。此外,在LLVM14及更高版本上,完成了多次outline的實現 ,相比于本文所述的單次outline,能夠進一步實現code size提升。
-
寄存器
+關注
關注
31文章
5363瀏覽量
121194 -
嵌入式系統
+關注
關注
41文章
3625瀏覽量
129760 -
編譯器
+關注
關注
1文章
1642瀏覽量
49289
發布評論請先 登錄
相關推薦
Coke Machine State Machine
JKI-State-Machine-Objects(SMO)框架講解
Brain Machine腦機器套件解析
vipm中 jki state machine
MCU也能做Machine learning嗎
Finite State Machine Datapath
Research on Human Machine Inte
Design Safe Verilog State Machine(Synplicity)

State Machine Coding Styles for Synthesis
EcoStruxure Machine Expert編程指南
使用Teachable Machine和Python輕松進行對象檢測






 工商網監
工商網監
評論