") NVIDIA為加速生成式AI而設(shè)計的超級芯片全面投產(chǎn)
NVIDIA為加速生成式AI而設(shè)計的超級芯片全面投產(chǎn)
2023年是大語言模型、生成式AI、ChatGPT、AIGC大爆發(fā)的一年。GPU是大規(guī)模深度學習、高性能計算的重要硬件基礎(chǔ),而大語言模型,如生成式AI、ChatGPT等,則借助GPU的計算能力快速地訓(xùn)練和推理,獲得更高的模型效果和更廣泛的應(yīng)用場景。尤其在游戲開發(fā)領(lǐng)域,運用大語言模型可以加強游戲的情節(jié)推進、人工智能角色表現(xiàn)等方面的體驗,而加速訓(xùn)練的英偉達GPU則可以使這些特征更加流暢。由于英偉達在GPU硬件設(shè)計和優(yōu)化方面的領(lǐng)先地位,為大型語言模型的快速發(fā)展提供了扎實的技術(shù)基礎(chǔ)。
目前中國和美國研發(fā)的大型AI模型數(shù)量占全球總數(shù)的80%以上,中國排名全球第二,僅次于美國,其中,已經(jīng)發(fā)布超過79個10億參數(shù)規(guī)模以上的大型AI模型。中國科學技術(shù)信息研究所所長、科技部新一代人工智能發(fā)展研究中心主任趙志耘表示,我國前期在人工智能領(lǐng)域的各項部署,為大模型發(fā)展奠定了堅實的基礎(chǔ),并已經(jīng)建立起涵蓋理論方法和軟硬件技術(shù)的體系化研發(fā)能力,形成了緊跟世界前沿的大模型技術(shù)群。
目前,我國參數(shù)規(guī)模在10億以上的大型AI模型數(shù)量達到79個,并且地域和領(lǐng)域分布相對于集中,全國14個省市/地區(qū)都在開展大模型研發(fā),主要集中在北京和廣東兩地,其中北京28個,廣東22個。同時,大模型應(yīng)用也在不斷拓展和深化落地。一方面,通用領(lǐng)域大模型如文心一言、通義千問、紫東太初、星火認知等正在快速發(fā)展,打造跨行業(yè)通用化人工智能能力平臺,其應(yīng)用行業(yè)在辦公、生活、娛樂向醫(yī)療、工業(yè)、教育等加速滲透;另一方面,針對生物制藥、遙感、氣象等垂直領(lǐng)域的專用大模型,發(fā)揮其領(lǐng)域縱深優(yōu)勢,提供針對特定業(yè)務(wù)場景的高質(zhì)量專業(yè)化解決方案。
5月29日,英偉達在2023臺北電腦展大會推出了DGX GH200 AI超級計算機,這是配備256顆Grace Hopper超級芯片和NVIDIA NVLink交換機系統(tǒng)的尖端系統(tǒng),具有1 exaflop性能和144TB共享內(nèi)存。該超級計算機的推出,在人工智能領(lǐng)域引起了轟動,標志著英偉達在大型AI模型技術(shù)和硬件設(shè)計領(lǐng)域的再次領(lǐng)先。其強大的計算和網(wǎng)絡(luò)技術(shù),為生成式AI、大型語言模型和推薦系統(tǒng)的應(yīng)用和開發(fā)帶來了更廣闊的前景,進一步拓展了AI的邊界。此外,DGX GH200還是第一臺Grace Hopper超級芯片和NVLink交換機系統(tǒng)配對的超級計算機,其帶寬較之前顯卡相比多48倍,為人工智能先驅(qū)和云服務(wù)提供商打開了探索新領(lǐng)域的大門。
DGX GH200與生成式AI
英偉達發(fā)布了一系列面向生成式AI的產(chǎn)品和服務(wù),包括大內(nèi)存生成式AI超級計算機DGX GH200、Grace Hopper超級芯片GH200的全面投產(chǎn)、全新加速以太網(wǎng)平臺Spectrum-X、定制化AI模型代工服務(wù)、與WPP合作打造生成式AI內(nèi)容引擎等,多項舉措都為生成式AI的應(yīng)用與發(fā)展提供了更廣闊的前景。
此外,英偉達還發(fā)布了MGX服務(wù)器規(guī)范,并且已有1600多家生成式AI公司采用了英偉達技術(shù)。
目前,英偉達市值已經(jīng)達到9632億美元,僅差一步之遙即可加入“萬億市值俱樂部”,成為美國上市公司市值排名第五的企業(yè)和第一家由華人創(chuàng)立的萬億美元市值公司。
E級算力,谷歌云、Meta、微軟首批試用
英偉達日前發(fā)布了一款采用最新GPU和CPU的系統(tǒng)巔峰之作——新型大內(nèi)存AI超級計算機DGX GH200,預(yù)計于今年年底上市。
該超算旨在支持生成式AI語言應(yīng)用、推薦系統(tǒng)和數(shù)據(jù)分析工作負載的大型下一代模型。DGX GH200集成了先進的加速計算和網(wǎng)絡(luò)技術(shù),是首款將Grace Hopper超級芯片與英偉達NVLink Switch系統(tǒng)搭配的超級計算機。
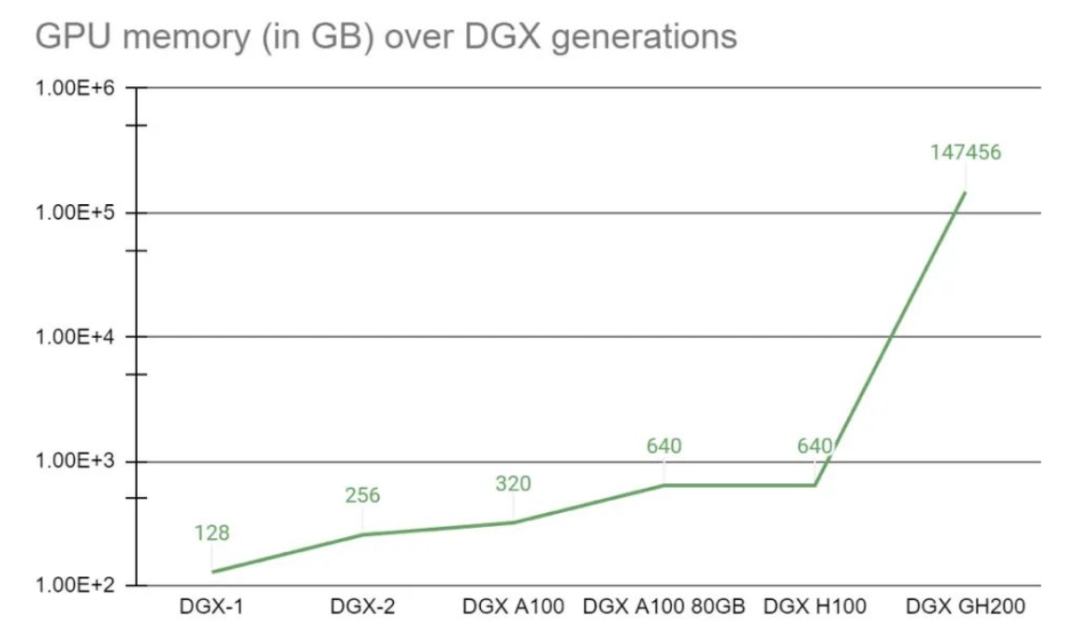
采用新互連方式,256個Grace Hopper超級芯片可以像單個巨型GPU一樣協(xié)同運行,提供了1EFLOPS性能和144TB共享內(nèi)存,比上一代DGX A100 320GB系統(tǒng)的內(nèi)存多出近500倍。
谷歌云、Meta、微軟等是首批獲得訪問權(quán)限的公司,英偉達打算將DGX GH200設(shè)計藍圖提供給其他云服務(wù)商及超大規(guī)模計算廠商,以便他們進一步為其基礎(chǔ)設(shè)施定制DGX GH200。
英偉達還正在打造自己的基于DGX GH200的大型AI超級計算機NVIDIA Helios,將于今年年底上線。此外,DGX GH200超級計算機包含英偉達軟件,提供AI工作流管理、企業(yè)級集群管理、加速計算、存儲和網(wǎng)絡(luò)基礎(chǔ)設(shè)施庫,以及100多個框架、預(yù)訓(xùn)練模型和開發(fā)工具,以簡化AI生產(chǎn)的開發(fā)和部署。
英偉達的Base Command軟件可以幫助管理AI工作流程、企業(yè)級集群、加速計算和存儲、網(wǎng)絡(luò)基礎(chǔ)設(shè)施等,而AI Enterprise軟件層則提供了許多框架、預(yù)訓(xùn)練模型和開發(fā)工具,以簡化AI生產(chǎn)的開發(fā)和部署。DGX GH200超級計算機的推出將有助于推動AI技術(shù)的發(fā)展,為各行各業(yè)提供更快、更強大的AI計算能力,加速AI技術(shù)的應(yīng)用和落地。
GH200芯片全面投產(chǎn)
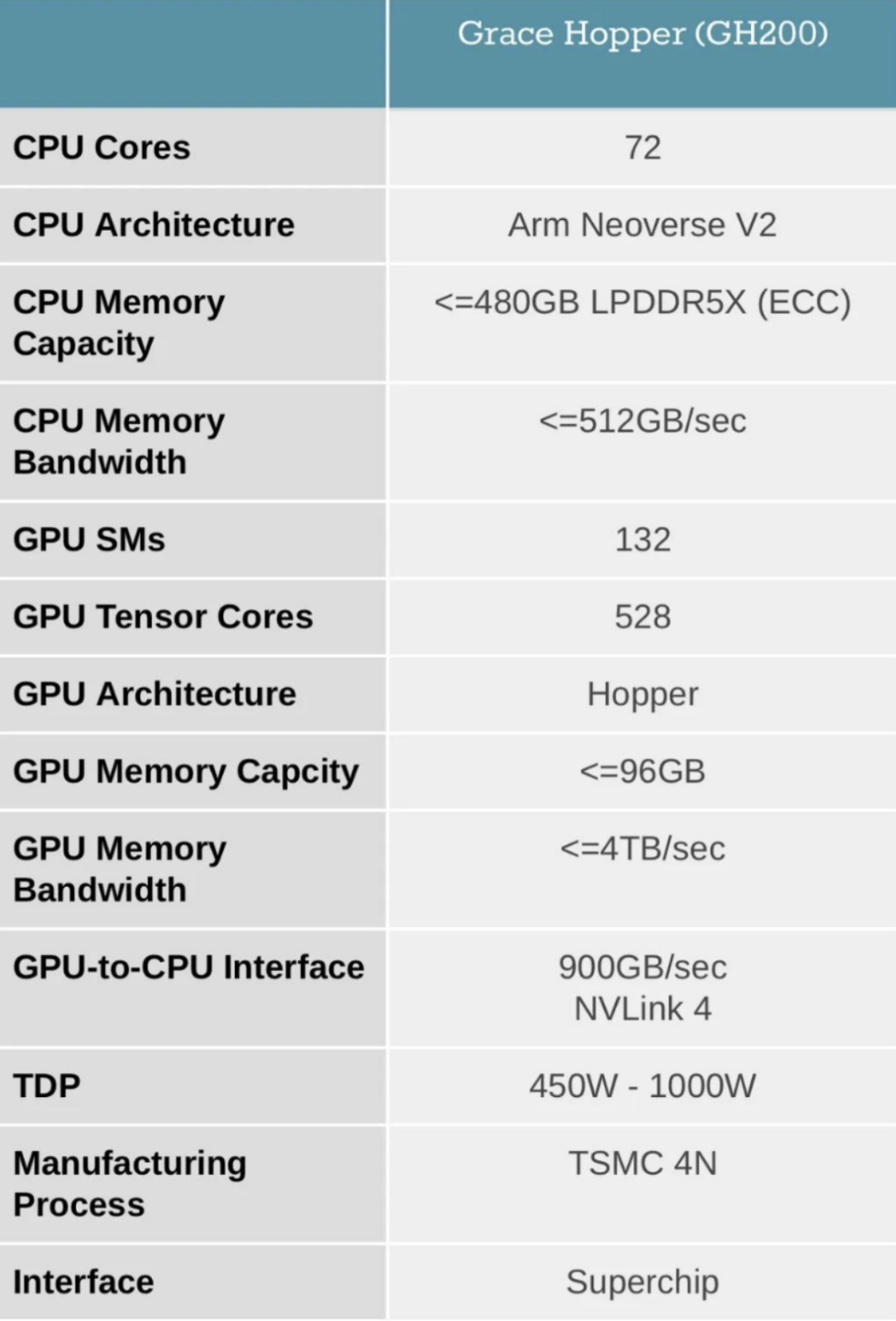
英偉達日前宣布,已全面投產(chǎn)GH200 Grace Hopper超級芯片,將為AI和高性能計算工作負載提供動力。
基于GH200的系統(tǒng)已經(jīng)被全球制造商采用,提供了超過400個配置,這些系統(tǒng)都基于英偉達的最新Grace Hopper和Ada Lovelace架構(gòu)。
GH200 Grace Hopper超級芯片采用了NVIDIA NVLink-C2C互連技術(shù),將英偉達Grace CPU和Hopper GPU架構(gòu)組合在同一封裝中,提供高達900GB/s的總帶寬,比傳統(tǒng)加速系統(tǒng)中的標準PCIe Gen5通道帶寬高7倍,同時互連功耗降低到原來的1/5,能夠滿足苛刻的生成式AI和高性能計算(HPC)應(yīng)用。預(yù)計幾家全球超大規(guī)模計算企業(yè)和超算中心客戶將采用GH200驅(qū)動的系統(tǒng),這些系統(tǒng)將于今年晚些時候上市。
打造數(shù)億美元生成式AI超算
此外,黃仁勛還宣布推出NVIDIA Spectrum-X平臺,旨在提高基于以太網(wǎng)的AI云的性能和效率。
Spectrum-X基于網(wǎng)絡(luò)創(chuàng)新,將英偉達Spectrum-4交換機和BlueField-3 DPU緊密耦合,實現(xiàn)了1.7倍的整體AI性能和能效提升,并通過性能隔離增強了多租戶功能,保持一致和可預(yù)測的性能。
Spectrum-X具有高度通用性,能夠用于各種AI應(yīng)用,與基于以太網(wǎng)的堆棧互操作,支持開發(fā)者構(gòu)建軟件定義的云原生AI應(yīng)用程序。全球各大云計算提供商正在采用Spectrum-X平臺擴展生成式AI服務(wù)。Spectrum-X、Spectrum-4交換機、BlueField-3 DPU等現(xiàn)已在戴爾、聯(lián)想、超微等系統(tǒng)制造商處提供。
NVIDIA正在以色列數(shù)據(jù)中心構(gòu)建一臺超大規(guī)模生成式AI超級計算機Israel-1作為Spectrum-X參考設(shè)計的藍圖和測試平臺。該超算將采用戴爾PowerEdge XE9680服務(wù)器、英偉達HGX H100超級計算平臺、內(nèi)置BlueField-3 DPU和Spectrum-4交換機的Spectrum-X平臺,預(yù)計價值數(shù)億美元。該平臺支持256個200Gb/s端口通過單個交換機連接,或在兩層leaf-spine拓撲中提供16000個端口,以支持AI云的增長和擴展,同時保持高水平的性能并最大限度地減少網(wǎng)絡(luò)延遲。
全球領(lǐng)先的云計算提供商正在采用Spectrum-X平臺擴展生成式AI服務(wù)。Spectrum-X、Spectrum-4交換機、BlueField-3 DPU等現(xiàn)已在戴爾、聯(lián)想、超微等系統(tǒng)制造商處提供。
MGX服務(wù)器規(guī)范
模塊化參考架構(gòu)
黃仁勛同時發(fā)布了NVIDIA MGX服務(wù)器規(guī)范,為系統(tǒng)制造商提供了模塊化參考架構(gòu),以適應(yīng)廣泛的AI、HPC及NVIDIA Omniverse應(yīng)用。
MGX支持英偉達全系列GPU、CPU、DPU和網(wǎng)絡(luò)適配器,以及各種x86及Arm處理器,這使得制造商能夠更有效地滿足每個客戶的獨特預(yù)算、電力輸送、熱設(shè)計和機械要求。
永擎(ASRock Rack)、華碩(ASUS)、技嘉(GIGABYTE)、和碩(Pegatron)、QCT、超微(Supermicro)等將采用MGX構(gòu)建下一代加速計算機,可將開發(fā)成本削減多達3/4,并將開發(fā)時間縮短2/3至僅需6個月。MGX可以從為其服務(wù)器機箱加速計算優(yōu)化的基本系統(tǒng)架構(gòu)開始,然后選擇GPU、DPU和CPU。同時,MGX提供了英偉達產(chǎn)品靈活的多代兼容性,以確保制造商可以重用現(xiàn)有設(shè)計并輕松采用下一代產(chǎn)品。MGX還能輕松集成到云和企業(yè)數(shù)據(jù)中心中。
除了MGX規(guī)范外,黃仁勛還宣布,英偉達與日本電信巨頭軟銀合作,在日本建立一個分布式數(shù)據(jù)中心網(wǎng)絡(luò)。該網(wǎng)絡(luò)將在一個共同的云平臺上提供5G服務(wù)和生成式AI應(yīng)用。數(shù)據(jù)中心將使用MGX系列(包括Grace Hopper、BlueField-3 DPU和Spectrum以太網(wǎng)交換機)以提供5G協(xié)議所需的高精度定時,并提高頻譜效率以降低成本和能耗。
這些系統(tǒng)有助于探索自動駕駛、AI工廠、AR/VR、計算機視覺和數(shù)字孿生等領(lǐng)域的應(yīng)用。未來的用途可能包括3D視頻會議和全息通信。這將為這些領(lǐng)域提供更高效、更靈活和更先進的解決方案,推動技術(shù)和產(chǎn)業(yè)的發(fā)展。
GH200在游戲行業(yè)的應(yīng)用
黃仁勛在宣布推出針對游戲的Avatar云引擎(ACE)服務(wù),這是一項定制AI模型代工服務(wù),中間件、工具和游戲開發(fā)者可以使用它來構(gòu)建和部署定制的語音、對話和動畫AI模型。
ACE能賦予非玩家角色(NPC)更智能且不斷進化的對話技能,使其能夠以栩栩如生的個性來回答玩家的問題。ACE for Games為語音、對話和角色動畫提供了優(yōu)化的AI基礎(chǔ)模型,包括:英偉達NeMo,使用專有數(shù)據(jù),構(gòu)建、定制和部署語言模型;英偉達Riva,用于自動語音識別和文本轉(zhuǎn)語音,以實現(xiàn)實時語音對話;英偉達Omniverse Audio2Face,用于即時創(chuàng)建游戲角色的表情動畫,以匹配任何語音軌道。
此外,英偉達與其子公司Convai合作,展示了如何快速用英偉達ACE for Games來構(gòu)建游戲NPU。在名為“Kairos”的演示中,英偉達展示了一個與一個拉面店的供應(yīng)商Jin互動的游戲。基于生成式AI,Jin雖是個NPC,卻能擬真地回答自然語言問題,且回答內(nèi)容與敘述的背景故事一致。開發(fā)人員可以集成整個NVIDIA ACE for Games解決方案,也可以只使用他們需要的組件。多家游戲開發(fā)商和初創(chuàng)公司已采用英偉達的生成式AI技術(shù)。
黃仁勛還介紹了英偉達和微軟如何在生成式AI時代合作推動Windows PC的創(chuàng)新。新的和增強的工具、框架和驅(qū)動程序使PC開發(fā)者更容易開發(fā)和部署AI,例如用于優(yōu)化和部署GPU加速AI模型和新圖形驅(qū)動程序的微軟Olive工具鏈將提高帶有英偉達GPU的Windows PC上的DirectML性能。此次合作將增強和擴展搭載RTX GPU的1億臺PC的安裝基礎(chǔ),可提升400多個AI加速的Windows應(yīng)用程序和游戲的性能。這將為PC游戲帶來更高的性能和更好的體驗,同時也將推動AI在Windows PC上的應(yīng)用和發(fā)展。
總的來說,黃仁勛在宣布中介紹了NVIDIA在游戲AI方面的最新進展和合作,包括Avatar云引擎(ACE)服務(wù)、微軟合作推動Windows PC的創(chuàng)新等。這些技術(shù)和合作將為游戲開發(fā)者帶來更多的AI工具和解決方案,為玩家?guī)砀玫挠螒蝮w驗。
DGX GH200在數(shù)字廣告中的應(yīng)用
英偉達的生成式AI技術(shù)也將在數(shù)字廣告行業(yè)帶來新機遇。基于NVIDIA AI和Omniverse技術(shù)的引擎將多個創(chuàng)意3D和AI工具連接在一起,以大規(guī)模革新商業(yè)內(nèi)容和體驗。
英國WPP集團,全球最大的營銷服務(wù)機構(gòu),正與英偉達合作,利用Omniverse Cloud構(gòu)建首個生成式AI內(nèi)容引擎,以更高效和高質(zhì)量的方式為客戶創(chuàng)建商業(yè)內(nèi)容。
新引擎連接了來自Adobe和Getty Images等工具的3D設(shè)計、制造和創(chuàng)意供應(yīng)鏈工具的生態(tài)系統(tǒng)。黃仁勛在演講中展示了創(chuàng)意團隊如何將他們的3D設(shè)計工具連接在一起,并在Omniverse中構(gòu)建客戶產(chǎn)品的數(shù)字孿生。使用負責任的數(shù)據(jù)來源訓(xùn)練生成式AI技術(shù)并結(jié)合英偉達Picasso一起構(gòu)建,使其能夠快速生成虛擬集。此后,WPP客戶可利用完整的場景生成大量廣告、視頻和3D體驗,供全球市場和用戶在任何網(wǎng)絡(luò)設(shè)備上使用。
這項合作在數(shù)字廣告領(lǐng)域持續(xù)推動著生成式AI技術(shù)的發(fā)展。WPP首席執(zhí)行官馬克·里德表示,生成式AI技術(shù)正在以驚人的速度改變營銷世界,合作所提供的獨特競爭優(yōu)勢將改變品牌為商業(yè)用途創(chuàng)建內(nèi)容的方式,并鞏固WPP在為世界頂級品牌創(chuàng)造性應(yīng)用AI方面的行業(yè)領(lǐng)導(dǎo)地位。
DGX GH200在
電子制造商中的應(yīng)用
全球電子制造商正在使用一種全新的綜合參考工作流程,這種工作流程結(jié)合了英偉達的多種技術(shù),包括生成式AI、3D協(xié)作、仿真和自主機器,旨在幫助制造商規(guī)劃、構(gòu)建、運營和優(yōu)化他們的工廠。這些技術(shù)包括英偉達的Omniverse,它連接了頂級計算機輔助設(shè)計和生成式AI的API和前沿框架;英偉達的Isaac Sim應(yīng)用程序,用于模擬和測試機器人;英偉達的Metropolis視覺AI框架,用于自動光學檢測。
英偉達使電子制造商能夠輕松構(gòu)建和運營虛擬工廠,將其制造和檢驗工作流程數(shù)字化,并大大提高質(zhì)量和安全,減少代價高昂的最后一刻意外和延誤。黃仁勛在現(xiàn)場展示了一個完全數(shù)字化的智能工廠的演示。
富士康工業(yè)互聯(lián)網(wǎng)、宜鼎國際、和碩、廣達和緯創(chuàng)正在使用英偉達的參考工作流程,以優(yōu)化他們的工作單元和裝配線運營,同時降低生產(chǎn)成本,具體用例包括電路板質(zhì)保檢測點自動化、光學檢測自動化、建設(shè)虛擬工廠、模擬協(xié)作機器人、構(gòu)建及運營數(shù)字孿生等。
英偉達正在與幾家領(lǐng)先的制造工具和服務(wù)提供商合作,構(gòu)建一個全棧、單一的架構(gòu),每個架構(gòu)都適用于每個工作流程級別。
在系統(tǒng)層面,英偉達IGX Orin提供了一個一體化的邊緣AI平臺,將工業(yè)級硬件與企業(yè)級軟件和支持相結(jié)合。IGX滿足邊緣計算獨特的耐用性和低功耗要求,同時提供開發(fā)和運行AI應(yīng)用程序所需的高性能。其制造商合作伙伴們正在開發(fā)IGX驅(qū)動的系統(tǒng),以服務(wù)于工業(yè)和醫(yī)療市場。
在平臺層面,Omniverse連接了世界領(lǐng)先的3D、模擬和生成式AI提供商,團隊可在他們最喜歡的應(yīng)用程序之間構(gòu)建互操作性,比如來自Adobe、Autodesk和Siemens的應(yīng)用程序。
這些技術(shù)的整合使得制造商能夠在一個統(tǒng)一的平臺上進行設(shè)計、仿真、測試和生產(chǎn),從而大大提高效率和質(zhì)量。此外,英偉達還提供了一系列工具和服務(wù),幫助制造商管理和優(yōu)化他們的生產(chǎn)線,包括實時監(jiān)控、數(shù)據(jù)分析和預(yù)測性維護。
英偉達的數(shù)字化工廠解決方案不僅適用于電子制造業(yè),還可以應(yīng)用于其他行業(yè),如汽車制造、航空航天、醫(yī)療設(shè)備等。這些行業(yè)都需要高度自動化和數(shù)字化的生產(chǎn)線,以滿足不斷增長的市場需求和質(zhì)量標準。
GH200產(chǎn)品參數(shù)
GH200是英偉達推出的最新超級計算機,最多可以放置256個GPU,適用于超大型AI模型的部署。相比之前的DGX服務(wù)器,GH200提供線性拓展方式和更高的GPU共享內(nèi)存編程模型,可通過NVLink高速訪問144TB內(nèi)存,是上一代DGX的500倍。其架構(gòu)提供的NVLink帶寬是上一代的48倍,使得千億或萬億參數(shù)以上的大模型能夠在一臺DGX內(nèi)放置,進一步提高模型效率和多模態(tài)模型的開發(fā)進程。
GPU的統(tǒng)一內(nèi)存編程模型一直是復(fù)雜加速計算應(yīng)用取得突破的基石。NVIDIA Grace Hopper Superchip與NVLink開關(guān)系統(tǒng)配對,在NVIDIA DGX GH200系統(tǒng)中整合了256個GPU,通過NVLink高速訪問144TB內(nèi)存。與單個NVIDIA DGX A100 320 GB系統(tǒng)相比,NVIDIA DGX GH200為GPU共享內(nèi)存編程模型提供了近500倍的內(nèi)存,是突破GPU通過NVLink訪問內(nèi)存的100TB障礙的第一臺超級計算機。NVIDIA Base Command的快速部署和簡化系統(tǒng)管理使用戶能夠更快地進行加速計算。
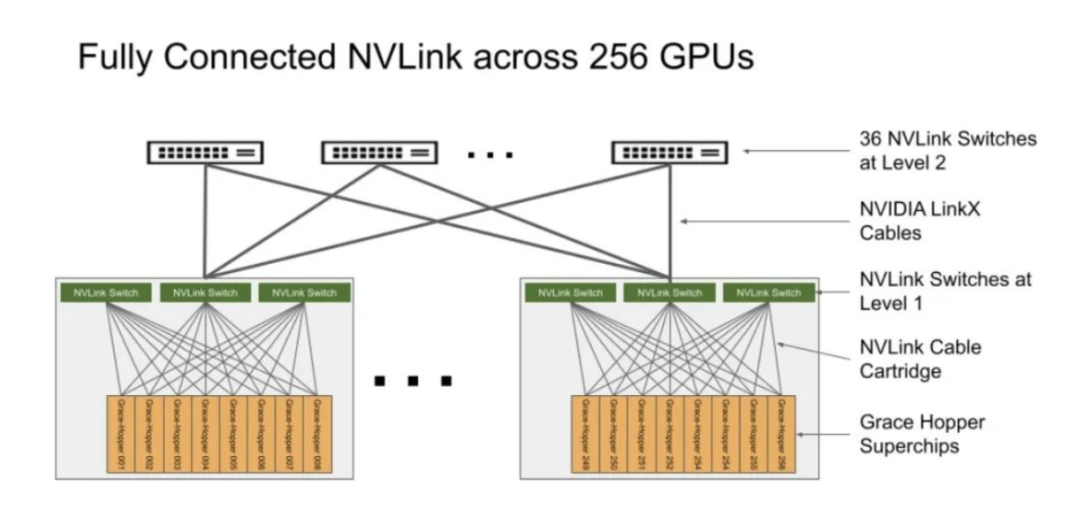
NVIDIA DGX GH200系統(tǒng)采用了NVIDIA Grace Hopper Superchip和NVLink Switch System作為其構(gòu)建塊。NVIDIA Grace Hopper Superchip將CPU和GPU結(jié)合在一起,使用NVIDIA NVLink-C2C技術(shù)提供一致性內(nèi)存模型,并提供高帶寬和無縫的多GPU系統(tǒng)。每個Grace Hopper超級芯片都擁有480GB的LPDDR5 CPU內(nèi)存和96GB的快速HBM3,提供比PCIe Gen5多7倍的帶寬,與NVLink-C2C互連。
NVLink開關(guān)系統(tǒng)使用第四代NVLink技術(shù),將NVLink連接擴展到超級芯片,以創(chuàng)建一個兩級、無阻塞、NVLink結(jié)構(gòu),可完全連接256個Grace Hopper超級芯片。這種結(jié)構(gòu)提供900GBps的內(nèi)存訪問速度,托管Grace Hopper Superchips的計算底板使用定制線束連接到第一層NVLink結(jié)構(gòu),并由LinkX電纜擴展第二層NVLink結(jié)構(gòu)的連接性。
在DGX GH200系統(tǒng)中,GPU線程可以使用NVLink頁表來訪問來自其他Grace Hopper超級芯片的內(nèi)存,并通過NVIDIA Magnum IO加速庫來優(yōu)化GPU通信以提高效率。該系統(tǒng)擁有128 TBps的對分帶寬和230.4 TFLOPS的NVIDIA SHARP網(wǎng)內(nèi)計算,可加速AI常用的集體運算,并將NVLink網(wǎng)絡(luò)系統(tǒng)的實際帶寬提高一倍。每個Grace Hopper Superchip都配備一個NVIDIA ConnectX-7網(wǎng)絡(luò)適配器和一個NVIDIA BlueField-3 NIC,以擴展到超過256個GPU,可以互連多個DGX GH200系統(tǒng),并利用BlueField-3 DPU的功能將任何企業(yè)計算環(huán)境轉(zhuǎn)變?yōu)榘踩壹铀俚奶摂M私有云。
對于受GPU內(nèi)存大小瓶頸的AI和HPC應(yīng)用程序,GPU內(nèi)存的代際飛躍可以顯著提高性能。對于許多主流AI和HPC工作負載,單個NVIDIA DGX H100的聚合GPU內(nèi)存可以完全支持。對于其他工作負載,例如具有TB級嵌入式表的深度學習推薦模型(DLRM)、TB級圖形神經(jīng)網(wǎng)絡(luò)訓(xùn)練模型或大型數(shù)據(jù)分析工作負載,使用DGX GH200可實現(xiàn)4至7倍的加速。這表明DGX GH200是更高級的AI和HPC模型的更好解決方案,這些模型需要海量內(nèi)存來進行GPU共享內(nèi)存編程。
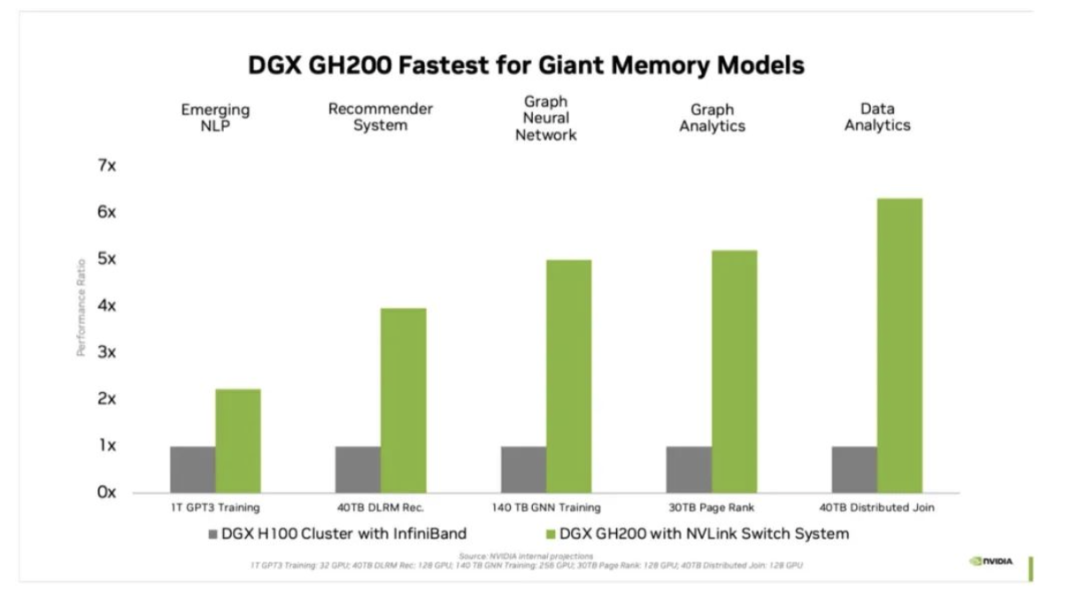
DGX GH200是專為最嚴苛的工作負載而設(shè)計的系統(tǒng),每個組件都經(jīng)過精心挑選,以最大限度地減少瓶頸,同時最大限度地提高關(guān)鍵工作負載的網(wǎng)絡(luò)性能,并充分利用所有擴展硬件功能。這使得該系統(tǒng)具有高度的線性可擴展性和海量共享內(nèi)存空間的高利用率。
為了充分利用這個先進的系統(tǒng),NVIDIA還構(gòu)建了一個極高速的存儲結(jié)構(gòu),以峰值容量運行并處理各種數(shù)據(jù)類型(文本、表格數(shù)據(jù)、音頻和視頻),并且表現(xiàn)穩(wěn)定且并行。
DGX GH200附帶NVIDIA Base Command,其中包括針對AI工作負載優(yōu)化的操作系統(tǒng)、集群管理器、加速計算的庫、存儲和網(wǎng)絡(luò)基礎(chǔ)設(shè)施,這些都針對DGX GH200系統(tǒng)架構(gòu)進行了優(yōu)化。此外,DGX GH200還包括NVIDIA AI Enterprise,提供一套經(jīng)過優(yōu)化的軟件和框架,可簡化AI開發(fā)和部署。這種全堆棧解決方案使客戶能夠?qū)W⒂趧?chuàng)新,而不必擔心管理其IT基礎(chǔ)架構(gòu)。
審核編輯:湯梓紅
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103723 -
AI
+關(guān)注
關(guān)注
87文章
31520瀏覽量
270339 -
英偉達
+關(guān)注
關(guān)注
22文章
3847瀏覽量
91976 -
超級芯片
+關(guān)注
關(guān)注
0文章
36瀏覽量
8912 -
生成式AI
+關(guān)注
關(guān)注
0文章
514瀏覽量
547
發(fā)布評論請先 登錄
相關(guān)推薦
聯(lián)發(fā)科與NVIDIA合作 為NVIDIA 個人AI超級計算機設(shè)計NVIDIA GB10超級芯片
NVIDIA 推出高性價比的生成式 AI 超級計算機

NVIDIA助力Amdocs打造生成式AI智能體
NVIDIA AI助力SAP生成式AI助手Joule加速發(fā)展
NVIDIA在加速計算和生成式AI領(lǐng)域的創(chuàng)新
NVIDIA攜手Meta推出AI服務(wù),為企業(yè)提供生成式AI服務(wù)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
NVIDIA宣布全面推出 NVIDIA ACE 生成式 AI 微服務(wù)
NVIDIA發(fā)布數(shù)字人微服務(wù),為制作生成式AI數(shù)字化身鋪平未來之路
NVIDIA數(shù)字人技術(shù)加速部署生成式AI驅(qū)動的游戲角色

NVIDIA生成式AI研究實現(xiàn)在1秒內(nèi)生成3D形狀

SAP與NVIDIA攜手加速生成式AI在企業(yè)應(yīng)用中的普及
NVIDIA 推出 Blackwell 架構(gòu) DGX SuperPOD,適用于萬億參數(shù)級的生成式 AI 超級計算






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論