") Python字符編碼轉(zhuǎn)換
Python字符編碼轉(zhuǎn)換
UNICODE字符串可以與任意字符編碼的字節(jié)進(jìn)行相互轉(zhuǎn)換,如圖:
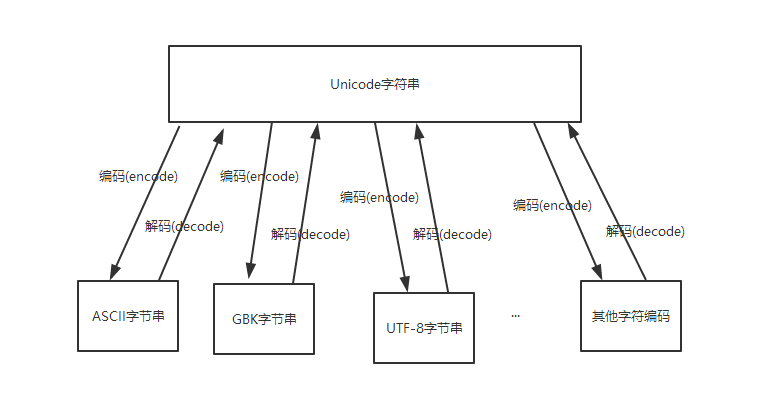
那么大家很容易想到一個(gè)問題,就是不同的字符編碼的字節(jié)可以通過Unicode相互轉(zhuǎn)換嗎?答案是肯定的。
Python2中的字符串進(jìn)行字符編碼轉(zhuǎn)換過程是:
字節(jié)串-->decode('原來的字符編碼')-->Unicode字符串-->encode('新的字符編碼')-->字節(jié)串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我愛中國'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
輸出結(jié)果:
我愛中國
Python3中定義的字符串默認(rèn)就是unicode,因此不需要先解碼,可以直接編碼成新的字符編碼:
字符串-->encode('新的字符編碼')-->字節(jié)串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我愛中國'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
輸出結(jié)果:
我愛中國
最后需要說明的是,Unicode不是有道詞典,也不是google翻譯器,它并不能把一個(gè)中文翻譯成一個(gè)英文。正確的字符編碼的轉(zhuǎn)換過程只是把同一個(gè)字符的字節(jié)表現(xiàn)形式改變了,而字符本身的符號(hào)是不應(yīng)該發(fā)生變化的,因此并不是所有的字符編碼之間的轉(zhuǎn)換都是有意義的。怎么理解這句話呢?比如GBK編碼的“中國”轉(zhuǎn)成UTF-8字符編碼后,僅僅是由4個(gè)字節(jié)變成了6個(gè)字節(jié)來表示,但其字符表現(xiàn)形式還應(yīng)該是“中國”,而不應(yīng)該變成“你好”或者“China”。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
編碼
+關(guān)注
關(guān)注
6文章
957瀏覽量
54951 -
字符
+關(guān)注
關(guān)注
0文章
234瀏覽量
25262 -
python
+關(guān)注
關(guān)注
56文章
4807瀏覽量
85038
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
C++字符編碼轉(zhuǎn)換的基本方法
這篇文章介紹了如何在最常見的編碼方式(Unicode, UTF-8, ANSI)之間進(jìn)行轉(zhuǎn)換,結(jié)合代碼實(shí)例,清晰明了,方便讀者理解,例子也可以直接拿來使用。本文推薦給經(jīng)常對(duì)文字字符串進(jìn)行處理的程序員閱讀,使其掌握
發(fā)表于 09-20 09:50
?2028次閱讀

從5個(gè)方面來解析計(jì)算機(jī)中的字符編碼概念
字符編碼是計(jì)算機(jī)編程中不可回避的問題,不管你用 Python2 還是 Python3,亦或是 C++, Java 等,我都覺得非常有必要厘清計(jì)算機(jī)中的

Python轉(zhuǎn)義字符使用總結(jié)資料免費(fèi)下載
本文檔的主要內(nèi)容詳細(xì)介紹的是Python轉(zhuǎn)義字符使用總結(jié)資料免費(fèi)下載主要內(nèi)容包括了:Python轉(zhuǎn)義字符,Python
發(fā)表于 01-17 17:24
?6次下載

Python字符的實(shí)例詳細(xì)說明
本文檔的主要內(nèi)容詳細(xì)介紹的是Python字符的實(shí)例詳細(xì)說明包括了:Python 轉(zhuǎn)義字符,Python
發(fā)表于 10-14 17:13
?7次下載

C++中字符編碼的轉(zhuǎn)換
。 這篇文章介紹了如何在最常見的編碼方式(Unicode, UTF-8, ANSI)之間進(jìn)行轉(zhuǎn)換,結(jié)合代碼實(shí)例,清晰明了,方便讀者理解,例子也可以直接拿來使用。本文推薦給經(jīng)常對(duì)文字字符串進(jìn)行處理的程序員閱讀,使其掌握
Python字符數(shù)統(tǒng)計(jì)函數(shù)程序
Python字符數(shù)統(tǒng)計(jì)函數(shù)程序免費(fèi)下載。
發(fā)表于 05-25 14:35
?19次下載
2.2 python字符串類型
2.2 python字符串類型 1. 如何定義字符串? 字符串是Python中最常用的數(shù)據(jù)類型之一。 使用單引號(hào)或雙引號(hào)來創(chuàng)建
python字符串有哪些特定方法
python字符串序列操作也適用于列表和元組。
python字符串還有獨(dú)有方法,即字符串對(duì)象的函數(shù),其他對(duì)象不可調(diào)用,只有
Python字符與字節(jié)
的不同的表示方法就是指字符編碼,比如字母A-Z都可以用ASCII碼表示(占用一個(gè)字節(jié)),也可以用UNICODE表示(占兩個(gè)字節(jié)),還可以用UTF-8表示(占用一個(gè)字節(jié))。字符編碼的作用
Python編碼與解碼
先做下科普:UNICODE字符編碼,也是一張字符與數(shù)字的映射,但是這里的數(shù)字被稱為代碼點(diǎn)(code point), 實(shí)際上就是十六進(jìn)制的數(shù)字。 Python官方文檔中對(duì)Unicode
Python中的默認(rèn)編碼
####1. Python源代碼文件的執(zhí)行過程 我們都知道,磁盤上的文件都是以二進(jìn)制格式存放的,其中文本文件都是以某種特定編碼的字節(jié)形式存放的。對(duì)于程序源代碼文件的字符編碼是由編輯器指
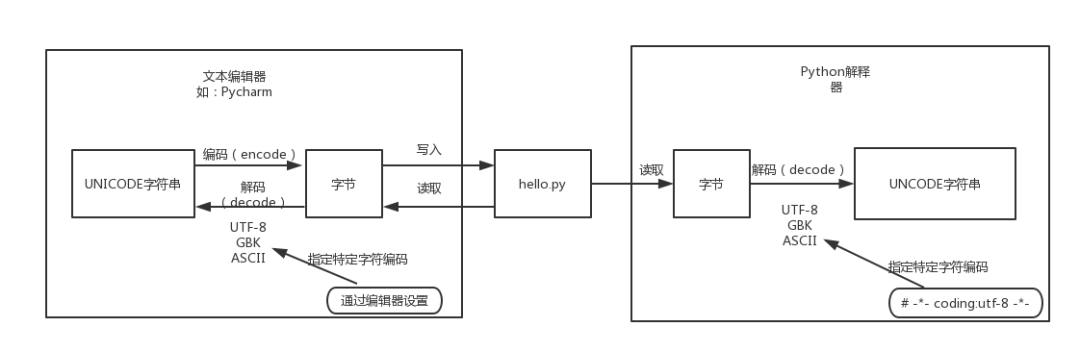
Python2與Python3中對(duì)字符串的支持
其實(shí)Python3中對(duì)字符串支持的改進(jìn),不僅僅是更改了默認(rèn)編碼,而是重新進(jìn)行了字符串的實(shí)現(xiàn),而且它已經(jīng)實(shí)現(xiàn)了對(duì)UNICODE的內(nèi)置支持,從這方面來講
mysql數(shù)據(jù)庫默認(rèn)字符編碼是什么
編碼是一種將字符映射到二進(jìn)制數(shù)據(jù)的方式。它定義了字符在計(jì)算機(jī)中的存儲(chǔ)和傳輸方式,決定了計(jì)算機(jī)如何解讀和顯示不同的字符。 為什么需要字符
如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法
決Python爬蟲中文亂碼問題。 一、了解字符編碼 在解決亂碼問題之前,我們首先需要了解一些基本的字符編碼知識(shí)。常見的





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論