") 利用Design Gateway的IP Core加速Xilinx VCK190評估套件上的AI應用
利用Design Gateway的IP Core加速Xilinx VCK190評估套件上的AI應用
Xilinx的Versal AI Core系列器件旨在解決有關 AI 推理的最大而獨特的難題,該系列使用具有高計算效率的 ASIC 級人工智能計算引擎以及靈活的可編程結構,來構建具有加速器的 AI 應用,以使任何給定的工作負載都能夠在實現(xiàn)低功耗、低延遲的同時達到最大效率。
Versal AI Core 系列VCK190 評估套件采用了該系列內 AI 性能最優(yōu)的VC1902 器件。該套件旨在用于需要高吞吐量 AI 推理和信號處理計算性能的設計。VCK190 套件提供比當前服務器級 CPU 高 100 倍的計算能力并提供各種連接選項,因而是適用于從云到邊緣計算等眾多應用的、理想的評估和原型開發(fā)平臺。

圖 1:Xilinx Versal AI Core 系列 VCK190 評估套件。(圖片來源:AMD, Inc)
VCK190 評估套件的主要特點
板載 Versal AI Core 系列器件
配備 Versal ACAP XCVC1902 生產(chǎn)芯片
AI 和 DSP 引擎擁有比當今服務器級 CPU 高 100 倍的計算能力
預先構建的合作伙伴參考設計用于快速原型設計
用于前沿應用開發(fā)的最新連接技術
內置第 4 代 PCIe? 硬 IP,用于高性能設備接口,如 NVMe SSD 和主機處理器
內置 100G EMAC 硬 IP,用于高速 100G 網(wǎng)絡接口
DDR4 和 LPDDR4 存儲器接口
協(xié)同優(yōu)化型工具和調試方法
Vivado? ML、Vitis? 統(tǒng)一軟件平臺、Vitis AI、AI 引擎工具,用于 AI 推理應用的開發(fā)
利用 Xilinx 的 Versal AI Core 系列器件進行 AI 接口加速
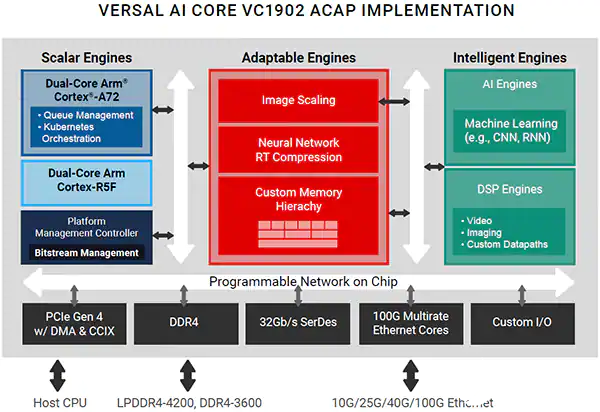
圖 2:Xilinx 的 Versal AI Core VC1902 ACAP 器件的框圖(圖片來源:AMD, Inc)
Versal? AI Core 自適應計算加速平臺 (ACAP) 是一個高度集成的多核異構器件,可以在硬件和軟件層面動態(tài)地適應各種 AI 工作負載,使其成為 AI 邊緣計算應用或云加速卡的理想選擇。該平臺集成了用于嵌入式計算的下一代 Scalar 引擎、用于提高硬件靈活性的自適應引擎以及由 DSP 引擎和用于推理和信號處理的革命性 AI 引擎組成的智能引擎。如此集成便形成了一款自適應性強的加速器,在 AI/ML 工作負荷方面超過了傳統(tǒng) FPGA 和 GPU 的性能、延遲和功率效率。
Versal ACAP 平臺的亮點
自適應性引擎:
自定義存儲器層次結構優(yōu)化了加速器內核的數(shù)據(jù)移動和管理
預處理和后處理功能包括神經(jīng)網(wǎng)絡 RT 壓縮和圖像縮放
AI 引擎 (DPU)
矢量處理器的平鋪陣列,通過 XCVC1902 器件達到 133 INT8 TOPS 性能,稱為深度學習處理單元或 DPU
非常適用于 CNN、RNN 和 MLP 等神經(jīng)網(wǎng)絡;為了適應不斷發(fā)展的算法,可對硬件進行優(yōu)化
標量引擎
四核 ARM 處理子系統(tǒng),用于安全、電源和比特流管理的平臺管理控制器
VCK190 AI 推理性能
相比目前的服務器級 CPU,VCK190 具有超過其 100 倍的計算性能。以下是一個基于 C32B6 DPU 內核(批處理 = 6)實現(xiàn)的 AI 引擎性能例子。請參考下表,了解 VCK190 上各種神經(jīng)網(wǎng)絡樣品的吞吐性能(以幀/秒或 fps 為單位),DPU 工作頻率 1250MHz。
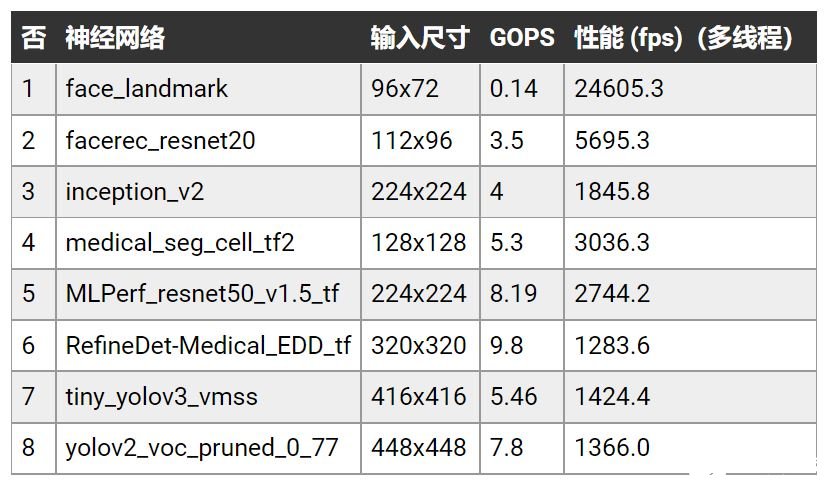
表1:VCK190 AI 推理性能示例。
更多關于 VCK190 AI 性能的詳細內容,請參見《Vitis AI Library User Guide (UG1354), r2.5.0》,網(wǎng)址:https://docs.xilinx.com/r/en-US/ug1354-xilinx-ai-sdk/VCK190-Evaluation-Board。
Design Gateway 的 IP 內核如何加速 AI 應用的性能?
Design GatewayIP 內核用來處理網(wǎng)絡和數(shù)據(jù)存儲協(xié)議,且不需要 CPU 干預。這使得該器件成為 CPU 系統(tǒng)完全擺脫復雜的協(xié)議處理的理想之選,使得這些系統(tǒng)能夠將大部分計算能力用于人工智能應用,包括人工智能推理、前后數(shù)據(jù)處理、用戶接口、網(wǎng)絡通信和數(shù)據(jù)存儲訪問,從而獲得最佳性能。
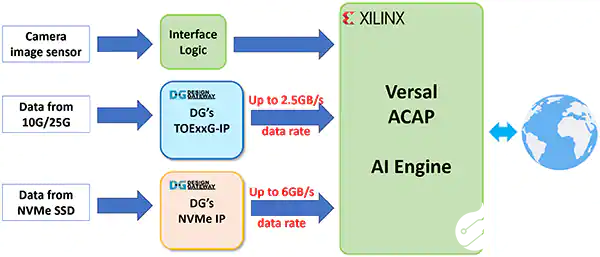
圖 3:使用 Design Gateway IP Core 的 AI 應用實例框圖(圖片來源:Design Gateway)
Design Gateway 的 TCP 卸載引擎 IP(TOExxG-IP)性能
用傳統(tǒng) CPU 系統(tǒng)處理 10GbE 或 25GbE 的高速、高吞吐量 TCP 數(shù)據(jù)流需要占用 50% 以上的 CPU 時間,這會降低 AI 應用的整體性能。根據(jù)在 Xilinx MPSoC Linux 系統(tǒng)上進行的 10G TCP 性能測試,在 10GbE TCP 傳輸過程中 CPU 的使用率超過 50%,TCP 發(fā)送和接收數(shù)據(jù)的傳輸速度可以達到 10GbE 速度的 40% 到 60% 左右,即 400 MB/s 到 600 MB/s。
通過實施 Design Gateway 的TOExxG-IP Core,在 10GbE 和 25GbE 上進行 TCP 傳輸?shù)?CPU 使用率可以降低到幾乎 0%,而以太網(wǎng)帶寬的利用率可接近100%。這允許通過純硬件邏輯直接在 TCP 網(wǎng)絡上發(fā)送和接收數(shù)據(jù),并以最低的 CPU 占用率和最低的延遲被送入 Versal AI 引擎。下方圖 4 顯示了 TOExxG-IP 和 MPSoC Linux 系統(tǒng)的 CPU 使用率和 TCP 傳輸速度對比。
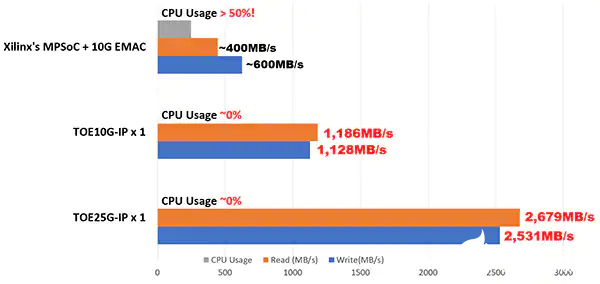
圖 4:MPSoC Linux 系統(tǒng)和 Design Gateway 的 TOExxG-IP Core 的 10G/25G TCP 傳輸?shù)男阅鼙容^。(圖片來源:Design Gateway)
Design Gateway 的 TOExxG-IP 用于 Versal 器件
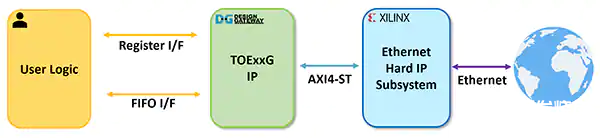
圖 5:TOExxG-IP 系統(tǒng)概覽。(圖片來源:Design Gateway)
TOExxG-IP 內核實現(xiàn)了 TCP/IP 協(xié)議棧(在硬線邏輯中)并與 Xilinx 的 EMAC 硬 IP 和以太網(wǎng)子系統(tǒng)模塊連接,以實現(xiàn) 10G/25G/100G 以太網(wǎng)速度的底層硬件接口。TOExxG-IP 的用戶接口包括一個用于控制信號的寄存器接口和一個用于數(shù)據(jù)信號的 FIFO 接口。TOExxG-IP 專用于通過 AXI4-ST 接口與 Xilinx 的以太網(wǎng)子系統(tǒng)連接。用戶接口的時鐘頻率取決于以太網(wǎng)接口的速度(例如 156.625 MHz 或 322.266 MHz)。
TOExxG-IP 的特點
完整的 TCP/IP 協(xié)議棧實施,不需要 CPU
支持與 TOExxG-IP 的一對一會話
多會話可以通過使用多個 TOExxG-IP 實例來實現(xiàn)
支持服務器和客戶端模式(被動/主動打開和關閉)
支持 Jumbo 框架
通過標準 FIFO 接口提供簡單的數(shù)據(jù)接口
XCVC1902-VSVA2197-2MP-ES FPGA 器件上的 FPGA 資源使用情況如下表 2 所列。

表 2:Versal 器件的實施統(tǒng)計示例。
有關 TOExxG-IP 的更多詳情,請參閱其規(guī)格書。可從 Design Gateway 網(wǎng)站下載規(guī)格書:
TOE10G-IP Core Xilinx 規(guī)格書
TOE25G-IP Core Xilinx 規(guī)格書
TOE100G-IP Core Xilinx 規(guī)格書
Design Gateway 的 NVMe 主機控制器 IP 性能
具有 PCIe Gen3 x4 或 PCIe Gen4 x4 的 NVMe 存儲器接口速度的數(shù)據(jù)速率分別高達 32Gbps 和 64Gbps。這比 10GbE 的以太網(wǎng)速度高三到六倍。CPU 處理復雜的 NVMe 存儲協(xié)議以達到最高的磁盤訪問速度;相比 10Gbe 以太網(wǎng)的 TCP 協(xié)議,這需要更多的 CPU 時間。
Design Gateway 通過開發(fā) NVMe IP 內核解決了該問題,該 IP 內核能夠作為獨立的 NVMe 主機控制器運行,能夠在沒有 CPU 參與的情況下直接與 NVMe SSD 通信。這使得 NVMe PCIe Gen3 和 Gen4 固態(tài)硬盤的訪問效率高、性能好,從而能夠簡化用戶接口和標準功能,實現(xiàn)了使用簡單,而不需要 NVMe 協(xié)議的知識。如圖 6 所示,NVMe PCIe Gen4 固態(tài)硬盤的性能可以通過 NVMe IP 實現(xiàn)高達 6GB/s 的傳輸速度。
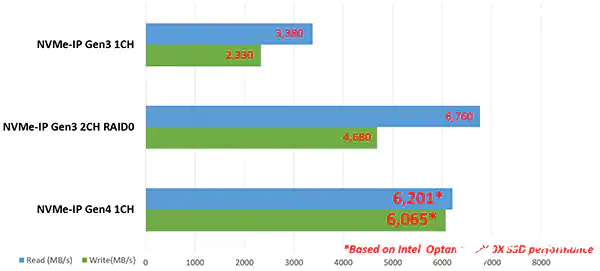
圖 6:NVMe PCIe Gen3 和 Gen4 SSD 與 Design Gateway 的 NVMe-IP Core 的性能比較。(圖片來源:Design Gateway)
用于 Versal 器件的 Design Gateway NVMe-IP
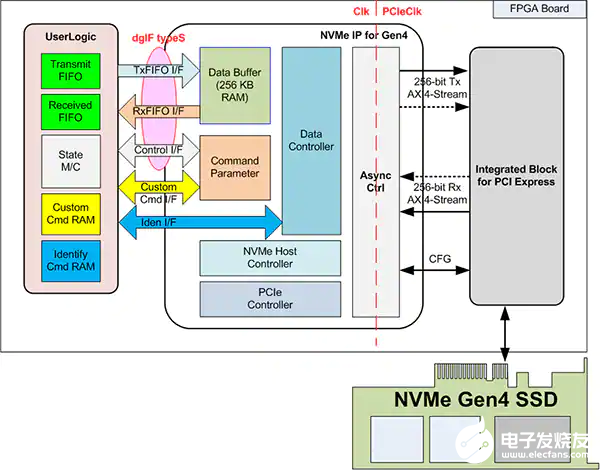
圖 7:NVMe-IP 系統(tǒng)概覽圖。(圖片來源:Design Gateway)
NVMe-IP 的特點
能夠實現(xiàn)應用層、事務層、數(shù)據(jù)鏈路層和物理層的某些部分在沒有 CPU 或外部 DDR 存儲器的情況下訪問 NVMe SSD
與 Xilinx PCIe Gen3 和 Gen4 Hard IP 一起使用
能夠利用 BRAM 和 URAM 作為數(shù)據(jù)緩沖器,而不需要外部存儲器接口
支持六條指令:識別、關斷、寫入、讀取、SMART 和刷新(可選擇支持其他命令)
XCVC1902-VSVA2197-2MP-E-S FPGA 器件的 FPGA 資源使用情況,如表 2 所示。

表 3:Versal 器件的實施統(tǒng)計示例。
有關 Versal 器件的 TOExxG-IP 的更多詳情,請參閱其規(guī)格書。可從 Design Gateway 網(wǎng)站下其載規(guī)格書:
Gen4 Xilinx 的 NVMe IP Core 規(guī)格書
結語
TOExxG-IP 和 NVMe-IP Core 通過使 CPU 系統(tǒng)完全擺脫計算和內存密集型協(xié)議(如 TCP 和 NVMe 存儲協(xié)議),來幫助加速人工智能應用的性能,這對實時人工智能應用至關重要。這使得 Xilinx 的 Versal AI Core 系列器件能夠執(zhí)行 AI 推理和高性能計算應用,而不會出現(xiàn)網(wǎng)絡和數(shù)據(jù)存儲協(xié)議處理的瓶頸或延誤。
VCK190 評估套件和 Design Gateway 的網(wǎng)絡和存儲 IP 解決方案能夠在 Xilinx 的 Versal AI Core 器件上以最低的 FPGA 資源占用率、極高的功率效率實現(xiàn) AI 應用的最佳性能。
審核編輯:湯梓紅
-
asic
+關注
關注
34文章
1206瀏覽量
120755 -
接口
+關注
關注
33文章
8691瀏覽量
151911 -
Xilinx
+關注
關注
71文章
2171瀏覽量
122127 -
AI
+關注
關注
87文章
31513瀏覽量
270323
發(fā)布評論請先 登錄
相關推薦
詳解基于賽靈思的Versal? ACAP設計創(chuàng)建步驟
如何在Linux平臺上進行Linux程序開發(fā)

利用設計網(wǎng)關的 IP 內核在 Xilinx VCK190 評估套件上加速人工智能應用
下載Xilinx IP Core
在Xilinx ZCU102評估套件上啟用NVMe SSD接口
利用設計網(wǎng)關的 IP 內核在 Xilinx VCK190 評估套件上加速人工智能應用
賽靈思Versal評估套件助力開發(fā)者邁入解鎖ACAP功能的高速路
賽靈思宣布兩款Versal ACAP評估套件現(xiàn)已上市
Vitis AI 1.4賦予 AI 產(chǎn)品化更多可能性
在VCK190板子上使用DDR4-DIMM的ECC
如何更改VCK190單板啟動模式
利用設計網(wǎng)關的 IP 內核在 Xilinx VCK190 評估套件上加速人工智能應用

【產(chǎn)品測試】利用設計網(wǎng)關的 IP 內核在 Xilinx VCK190 評估套件上加速人工智能應用
在Versal VCK190評估套件上使用器件固件升級(DFU)執(zhí)行USB輔助啟動模式測試







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論