 基礎模型自監督預訓練的數據之謎:大量數據究竟是福還是禍?
基礎模型自監督預訓練的數據之謎:大量數據究竟是福還是禍?
 ?論文標題:Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts
?論文標題:Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts論文鏈接:
https://openreview.net/forum?id=j8IiQUM33s
此外,團隊還提出了一種名為混合自編碼器 (MixedAE) 的簡單而有效的方法,將圖像混合應用于 MAE 數據增強。MixedAE 在各種下游任務(包括圖像分類、語義分割和目標檢測)上實現了最先進的遷移性能,同時保持了顯著的效率。這是第一個從任務設計的角度將圖像混合作為有效數據增強策略應用于基于純自編碼器結構的 Masked Image Modeling (MIM) 的研究。該工作已被 CVPR 2023 會議接收。

論文鏈接:
https://arxiv.org/abs/2303.17152 ?
?研究背景
在機器學習領域,預訓練模型已經成為一種流行的方法,可以提高各種下游任務的性能。然而,研究發現,自監督預訓練存在的負遷移現象。諾亞 AI 基礎理論團隊的前期工作 SDR (AAAI 2022) [1] 首次指出自監督預訓練的負遷移問題,并提供初步解決方案。具體來說,負遷移是指在預訓練過程中使用的數據與下游任務的數據分布不同,導致預訓練模型在下游任務上的性能下降。在自監督學習中,模型在無標簽數據上進行預訓練,學習數據的潛在特征和表示。然而,當預訓練數據與下游任務的數據分布存在顯著差異時,模型可能學到與下游任務無關或甚至有害的特征。
 ?相關工作1. 自監督預訓練的負遷移現象
?相關工作1. 自監督預訓練的負遷移現象
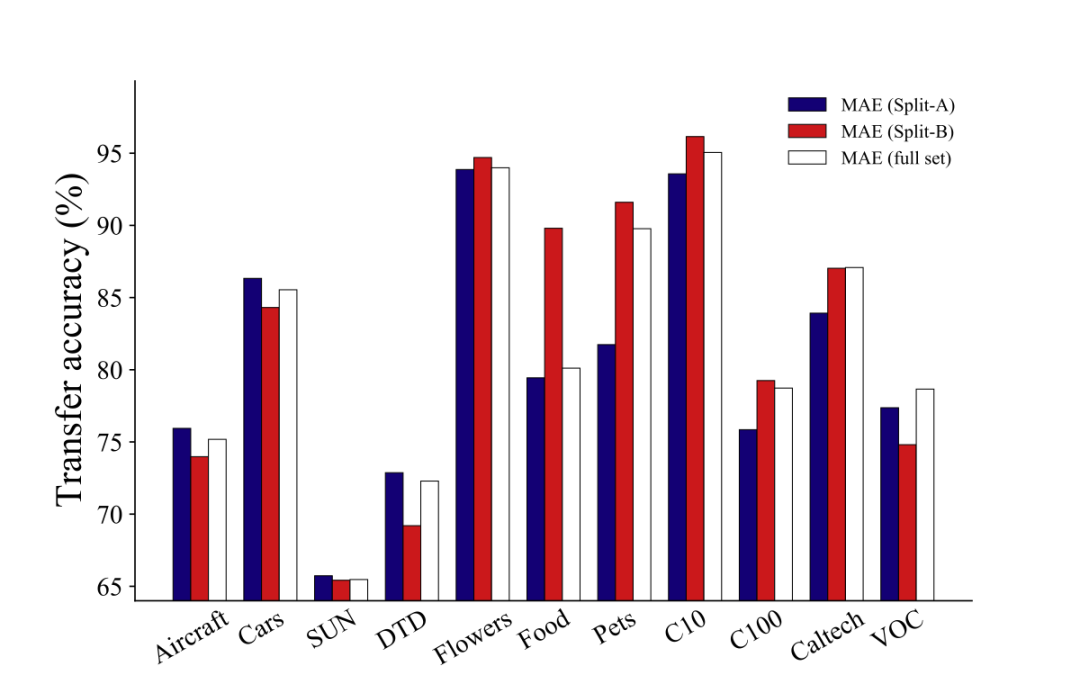
▲圖一:我們用ImageNet的兩個子集,Split-A和Split-B,訓練兩個MAE模型,和全量數據集訓練的模型相比較,后者僅在2個數據集上達到了最優。這說明,增大數據量并不總是帶來更強的遷移效果。
以目前較為流行的自監督學習算法 MAE 為例,我們評估了使用不同語義數據進行預訓練的 MAE 模型在遷移性能上的表現。我們將 ImageNet 數據集分為兩個不相交的子集 Split-A 和 Split-B,根據 WordNet 樹中標簽的語義差異進行劃分。Split-A 主要包含無生命物體(如汽車和飛機),而 Split-B 則主要涉及有機體(如植物和動物)。接著,我們在 Split-A、Split-B 和完整的 ImageNet 數據集上分別進行了 MAE 預訓練,并在 11 個下游任務上評估了這三個模型的性能。如圖一所示,在僅含 2 個語義豐富數據集(Caltech,VOC)的情況下,基于完整 ImageNet 訓練的 MAE 獲得了最佳的遷移效果;在非生物下游數據集 (Aircraft,Cars,SUN,DTD) 上,Split-A 的表現更佳;而在包含 Flowers,Food,Pets,CIFAR10,CIFAR100 等數據集上,Split-B 的表現更優。這表明,當下游任務與預訓練數據分布不同時,與任務無關的預訓練信息可能導致負遷移,從而限制了 MAE 模型的可擴展性。換言之,若一個 MAE 模型的預訓練數據去除了與下游任務數據集相似度較低的部分,則其性能可能優于包含這些無關數據的預訓練模型。這突顯了開發針對特定下游任務的定制化預訓練方法以避免負遷移現象的重要性。2. 自監督數據增強難題在自監督預訓練中,與依賴數據增強的對比學習不同,我們發現傳統數據增強手段可能會削弱 MAE 的模型性能。以圖像混合增強(Image Mixing)為例,設隨機變量 X1 和 X2 表示兩個輸入圖像,M 表示隨機生成的掩碼,我們可以證明混合輸入 σmix({X1,X2},M) 與重構目標 X1 之間的互信息 (MI) 不小于 MAE 輸入 σmae(X1,M) 與 X1 之間的互信息(詳見論文附錄)。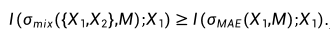 因此,簡單的圖像混合增強會提升模型輸入與重構目標之間的互信息。盡管這對監督學習和對比學習有益,但它卻簡化了 MAE 的圖像重構任務,因為掩碼操作 (masking) 的根本目的恰恰是降低模型輸入和重構目標之間的互信息,以減少圖像信號的冗余。這表明以 MAE 為代表的掩碼圖像建模對數據增強具有與傳統判別式訓練范式不同的偏好,進而帶來了 MAE 自監督學習中的數據增強難題。
因此,簡單的圖像混合增強會提升模型輸入與重構目標之間的互信息。盡管這對監督學習和對比學習有益,但它卻簡化了 MAE 的圖像重構任務,因為掩碼操作 (masking) 的根本目的恰恰是降低模型輸入和重構目標之間的互信息,以減少圖像信號的冗余。這表明以 MAE 為代表的掩碼圖像建模對數據增強具有與傳統判別式訓練范式不同的偏好,進而帶來了 MAE 自監督學習中的數據增強難題。
 ?方法1. MoCEMixture of Cluster-conditional Expert (MoCE) 通過數據聚類和顯式地使用具有相似語義的圖像來訓練每個專家,以實現針對特定任務的定制自監督預訓練。MoCE 的過程分為三個階段,具體如下:1. 首先,我們使用預先訓練好的 MAE 模型對整個數據集進行聚類。每張圖片被分到不同的聚類中,并記錄每個聚類的中心點,形成矩陣 C。2. 然后,受 Mixture-of-Experts (MoE) 多專家模型的啟發,我們構建了基于聚類先驗的 MoCE 模型。與目前常用的視覺多專家模型將每個圖像的 token 路由到某個專家不同,MoCE 讓每個專家負責訓練一組相似的聚類圖片,使得每個專家在不同語義數據上得到顯式訓練。具體來說,現有的視覺多專家模型基于 ViT 構建,將原先某些 Transformer Block 中的單個 MLP 層擴展為多個 MLP 層,每個 MLP 被稱作一個專家 (expert)。同時引入一個門控網絡 (gate network),該門控網絡決定每個 token 應該去往哪個專家。MoCE 多專家層的核心改變是門控網絡的輸入:
?方法1. MoCEMixture of Cluster-conditional Expert (MoCE) 通過數據聚類和顯式地使用具有相似語義的圖像來訓練每個專家,以實現針對特定任務的定制自監督預訓練。MoCE 的過程分為三個階段,具體如下:1. 首先,我們使用預先訓練好的 MAE 模型對整個數據集進行聚類。每張圖片被分到不同的聚類中,并記錄每個聚類的中心點,形成矩陣 C。2. 然后,受 Mixture-of-Experts (MoE) 多專家模型的啟發,我們構建了基于聚類先驗的 MoCE 模型。與目前常用的視覺多專家模型將每個圖像的 token 路由到某個專家不同,MoCE 讓每個專家負責訓練一組相似的聚類圖片,使得每個專家在不同語義數據上得到顯式訓練。具體來說,現有的視覺多專家模型基于 ViT 構建,將原先某些 Transformer Block 中的單個 MLP 層擴展為多個 MLP 層,每個 MLP 被稱作一個專家 (expert)。同時引入一個門控網絡 (gate network),該門控網絡決定每個 token 應該去往哪個專家。MoCE 多專家層的核心改變是門控網絡的輸入: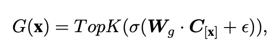 這里,C[x] 表示 token x 所屬圖片所在的聚類中心(我們在第一步已經完成了聚類),而不是原先的 token 嵌入。這樣,屬于同一個聚類的圖片的 tokens 都會被路由到同一個專家,從而顯式地區分每個專家在語義上的差異。為了穩定訓練并增強門控網絡的置信度,我們提出了兩個額外的正則化損失,并在實驗中發現了它們的有效性。3. 當下游任務到達時,我們引入了一個搜索模塊來選擇最適合用于遷移學習的專家。具體而言,我們重復利用第一步提到的聚類模塊,找到與下游數據集最相似的聚類,然后找到該聚類所訓練的專家,將其單獨提取出來,舍棄其他專家進行遷移。這樣,在下游任務中,我們始終使用一個正常大小的 ViT 模型。2. MixedAEMixed Autoencoder (MixedAE) 提出輔助代理任務——同源識別(Homologous recognition),旨在顯示要求每個圖像塊識別混合圖像中的同源圖像塊以緩解圖像混合所導致的互信息上升,從而實現物體感知的自監督預訓練。MixedAE 的過程分為三個階段,具體如下:1. 混合階段:在給定混合系數 r 的情況下,將輸入圖像隨機劃分為不同的圖像組,并根據 r 對每個圖像組進行隨機混合,生成混合圖像。2. 識別階段:鑒于 Vision Transformer 中全局自注意力的使用,在重構過程中,各個圖像塊不可避免地與來自其他圖像的異源圖像塊發生交互,從而導致互信息的上升。因此我們提出同源自注意力機制 (Homologous attention),通過部署一個簡單的 TopK 采樣操作,要求每個圖像塊顯示識別并僅與同源圖像塊做自注意力計算,以抑制互信息的上升。
這里,C[x] 表示 token x 所屬圖片所在的聚類中心(我們在第一步已經完成了聚類),而不是原先的 token 嵌入。這樣,屬于同一個聚類的圖片的 tokens 都會被路由到同一個專家,從而顯式地區分每個專家在語義上的差異。為了穩定訓練并增強門控網絡的置信度,我們提出了兩個額外的正則化損失,并在實驗中發現了它們的有效性。3. 當下游任務到達時,我們引入了一個搜索模塊來選擇最適合用于遷移學習的專家。具體而言,我們重復利用第一步提到的聚類模塊,找到與下游數據集最相似的聚類,然后找到該聚類所訓練的專家,將其單獨提取出來,舍棄其他專家進行遷移。這樣,在下游任務中,我們始終使用一個正常大小的 ViT 模型。2. MixedAEMixed Autoencoder (MixedAE) 提出輔助代理任務——同源識別(Homologous recognition),旨在顯示要求每個圖像塊識別混合圖像中的同源圖像塊以緩解圖像混合所導致的互信息上升,從而實現物體感知的自監督預訓練。MixedAE 的過程分為三個階段,具體如下:1. 混合階段:在給定混合系數 r 的情況下,將輸入圖像隨機劃分為不同的圖像組,并根據 r 對每個圖像組進行隨機混合,生成混合圖像。2. 識別階段:鑒于 Vision Transformer 中全局自注意力的使用,在重構過程中,各個圖像塊不可避免地與來自其他圖像的異源圖像塊發生交互,從而導致互信息的上升。因此我們提出同源自注意力機制 (Homologous attention),通過部署一個簡單的 TopK 采樣操作,要求每個圖像塊顯示識別并僅與同源圖像塊做自注意力計算,以抑制互信息的上升。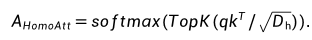 3. 驗證階段:為了驗證同源自注意力的準確性,我們提出同源對比損失 (Homologous contrasitve)。對于任意查詢圖像塊 (query patch),我們將其同源圖像塊視為正樣本,異源圖像塊作為負樣本,以促進同源圖像塊特征的相似度,從而顯示要求圖像塊識別并僅和同源圖像塊做自注意力計算。最后,同源對比損失將和原始圖像重構損失一起以多任務形式優化網絡參數進行自監督預訓練。
3. 驗證階段:為了驗證同源自注意力的準確性,我們提出同源對比損失 (Homologous contrasitve)。對于任意查詢圖像塊 (query patch),我們將其同源圖像塊視為正樣本,異源圖像塊作為負樣本,以促進同源圖像塊特征的相似度,從而顯示要求圖像塊識別并僅和同源圖像塊做自注意力計算。最后,同源對比損失將和原始圖像重構損失一起以多任務形式優化網絡參數進行自監督預訓練。
 ?
?實驗分析
1. MoCE我們在之前提到的 11 個下游分類數據集和檢測分割任務上做了實驗。實驗結果表明,MoCE 在多個下游任務中的性能超過了傳統的 MAE 預訓練方法。具體而言,在圖像分類任務中,MoCE 相較于 MAE 實現了更高的準確率。在目標檢測和分割任務中,MoCE 也取得了更好的表現,包括更高的 mIoU 和 AP 指標。這些實驗結果表明,MoCE 通過利用相似語義圖像進行聚類并為每個專家進行任務定制的自監督預訓練,能夠在各種下游任務中提高遷移性能。
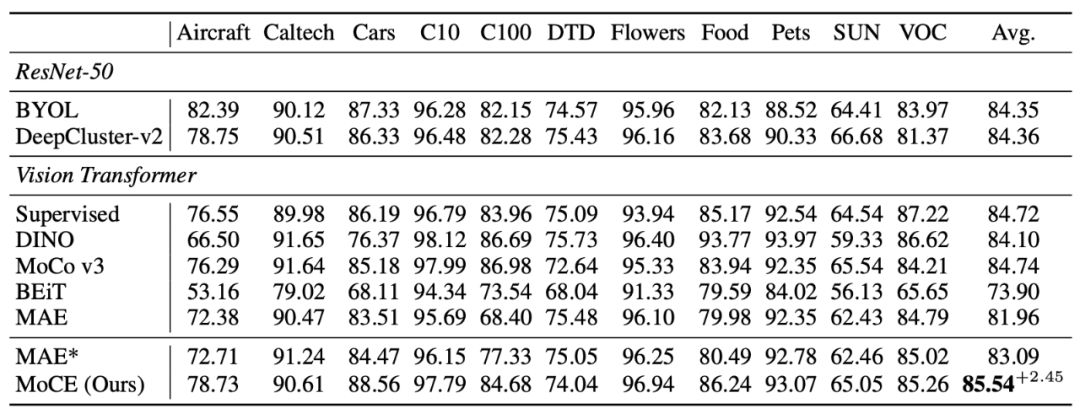 ▲表一:MoCE在細粒度數據集上有較大提升,在類別比較寬泛的任務上也有少量提升。2. MixedAE
▲表一:MoCE在細粒度數據集上有較大提升,在類別比較寬泛的任務上也有少量提升。2. MixedAE在 14 個下游視覺任務(包括圖像分類、語義分割和物體檢測)的評估中,MixedAE 展現了最優的遷移性能和卓越的計算效率。相較于 iBOT,MixedAE 實現了約 2 倍預訓練加速。得益于圖像混合所帶來的物體感知預訓練,MixedAE 在下游密集預測任務上取得更顯著的性能提升。注意力圖可視化結果表明,MixedAE 能比 MAE 更準確完整地識別圖像前景物體,從而實現優異的密集預測遷移性能。
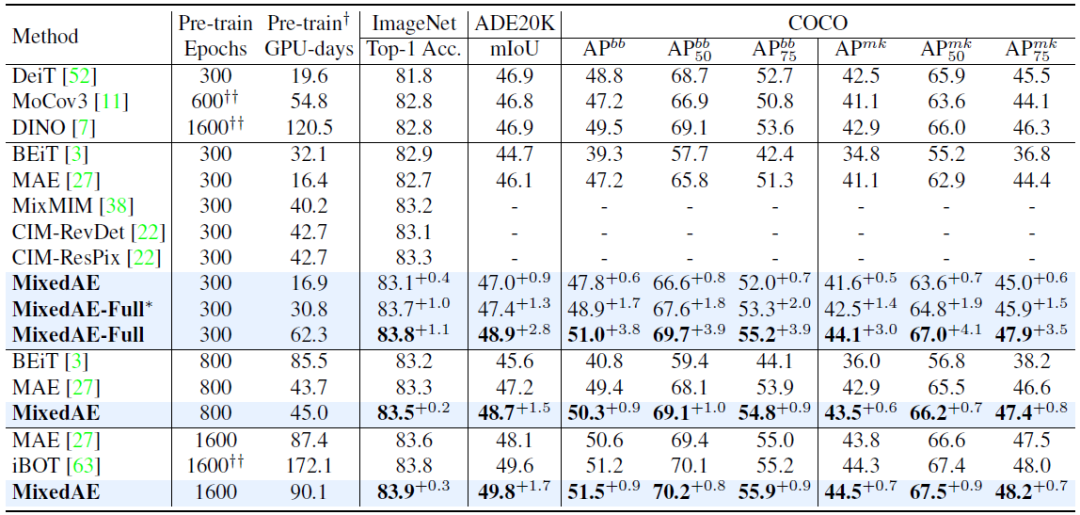 ▲表二:MixedAE在不同訓練代價下均獲得當前最優結果,展現了卓越的計算效率。
▲表二:MixedAE在不同訓練代價下均獲得當前最優結果,展現了卓越的計算效率。
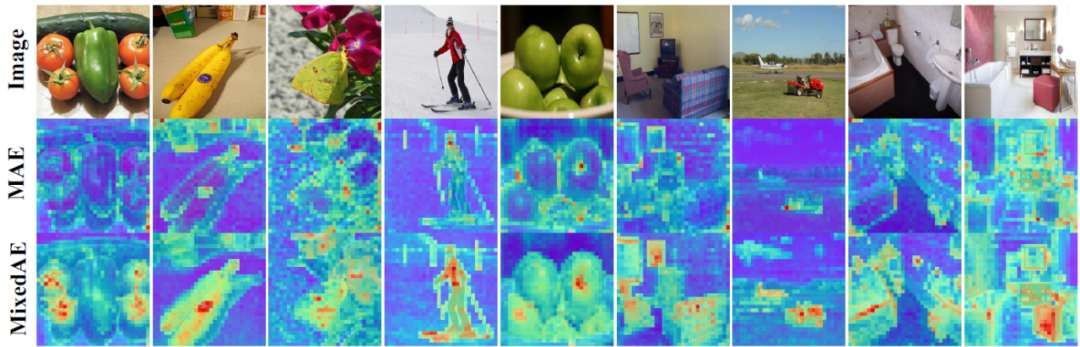
▲圖二:注意力圖可視化。得益于ImageNet的單實例假設[2]以及物體感知的自監督預訓練,MixedAE可以更準確完整地發現圖像前景物體,從而實現更好的密集預測遷移性能。
 ?作者介紹結合 MoCE 和 MixedAE 的研究發現,我們揭示了自監督預訓練中數據之謎:數據量不再是唯一關鍵因素,而是如何利用數據和進行定制化預訓練和數據增廣更為關鍵。MoCE 通過數據聚類和專家定制訓練,顯著提高了針對特定下游任務的遷移性能。MixedAE 則通過一種簡單有效的圖像混合方法,實現了在各種下游任務中的最先進遷移性能。這些研究發現不僅為自監督預訓練領域提供了新的視角,還為開發更為高效、可擴展和定制化的預訓練方法提供了指導和啟示。我們希望這些探索是一個有效利用更多數據量的途徑,并為研究者們提供新的思路。
?作者介紹結合 MoCE 和 MixedAE 的研究發現,我們揭示了自監督預訓練中數據之謎:數據量不再是唯一關鍵因素,而是如何利用數據和進行定制化預訓練和數據增廣更為關鍵。MoCE 通過數據聚類和專家定制訓練,顯著提高了針對特定下游任務的遷移性能。MixedAE 則通過一種簡單有效的圖像混合方法,實現了在各種下游任務中的最先進遷移性能。這些研究發現不僅為自監督預訓練領域提供了新的視角,還為開發更為高效、可擴展和定制化的預訓練方法提供了指導和啟示。我們希望這些探索是一個有效利用更多數據量的途徑,并為研究者們提供新的思路。

參考文獻
?[1] Task-customized Self-supervised Pre-training with Scalable Dynamic Routing, AAAI 2022.
[2] MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving, ICCV 2021.
·
-
物聯網
+關注
關注
2913文章
44929瀏覽量
377064
原文標題:基礎模型自監督預訓練的數據之謎:大量數據究竟是福還是禍?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCM1861 INT腳究竟是輸出還是輸入?
AI大模型的訓練數據來源分析
直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論