 NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
論文簡介
可控擴散模型如ControlNet、T2I-Adapter和GLIGEN等可通過額外添加的空間條件如人體姿態、目標框來控制生成圖像中內容的具體布局。使用從已有的圖像中提取的人體姿態、目標框或者數據集中的標注作為空間限制條件,上述方法已經獲得了非常好的可控圖像生成效果。那么如何更友好、方便地獲得空間限制條件?或者說如何自定義空間條件用于可控圖像生成呢?例如自定義空間條件中物體的類別、大小、數量、以及表示形式(目標框、關鍵點、和實例掩碼)。
本文將空間條件中物體的形狀、位置以及它們之間的關系等性質總結為視覺先驗(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式來建模上述視覺先驗。因此,我們可以從學習好的先驗中通過Prompt從多個層面,例如表示形式(目標框、關鍵點、實例掩碼)、物體類別、大小和數量,來采樣空間限制條件。我們設想,隨著可控擴散模型生成能力的提升,以此可以針對性地生成圖像用于特定場景下的數據補充,例如擁擠場景下的人體姿態估計和目標檢測。
方法介紹
表1 訓練數據
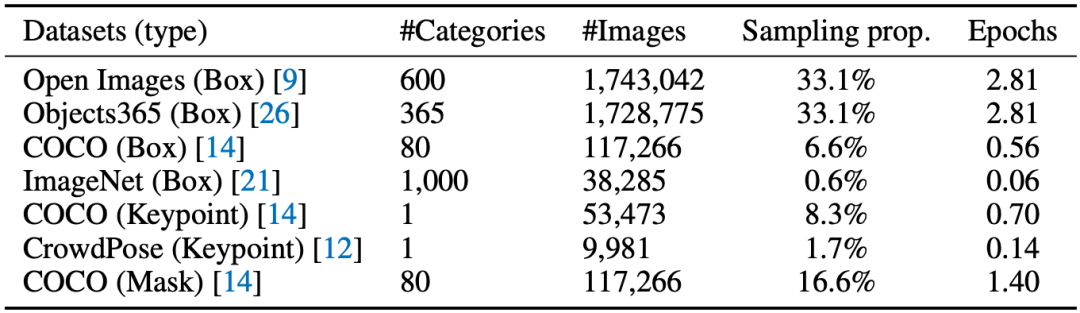
本文從當前公開的數據集中整理收集了七種數據,如表1所示。為了以Generative Pre-Training的方式學習視覺先驗并且添加序列輸出的可定制功能,本文提出以下兩種Prompt模板:

使用上述模板可以將表1中訓練數據中每一張圖片的標注格式化成一個序列x。在訓練過程中,我們使用BPE算法將每個序列x編碼成tokens={u1,u2,…,u3},并通過極大化似然來學習視覺先驗,如下式:
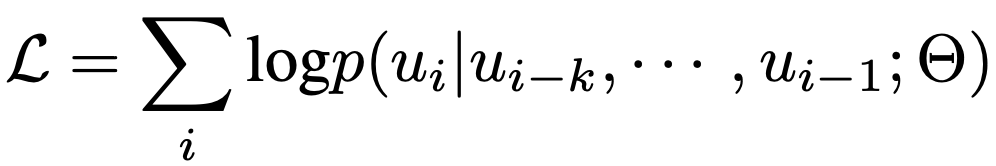
最后,我們可以從上述方式學習獲得的模型中定制序列輸出,如下圖所示。
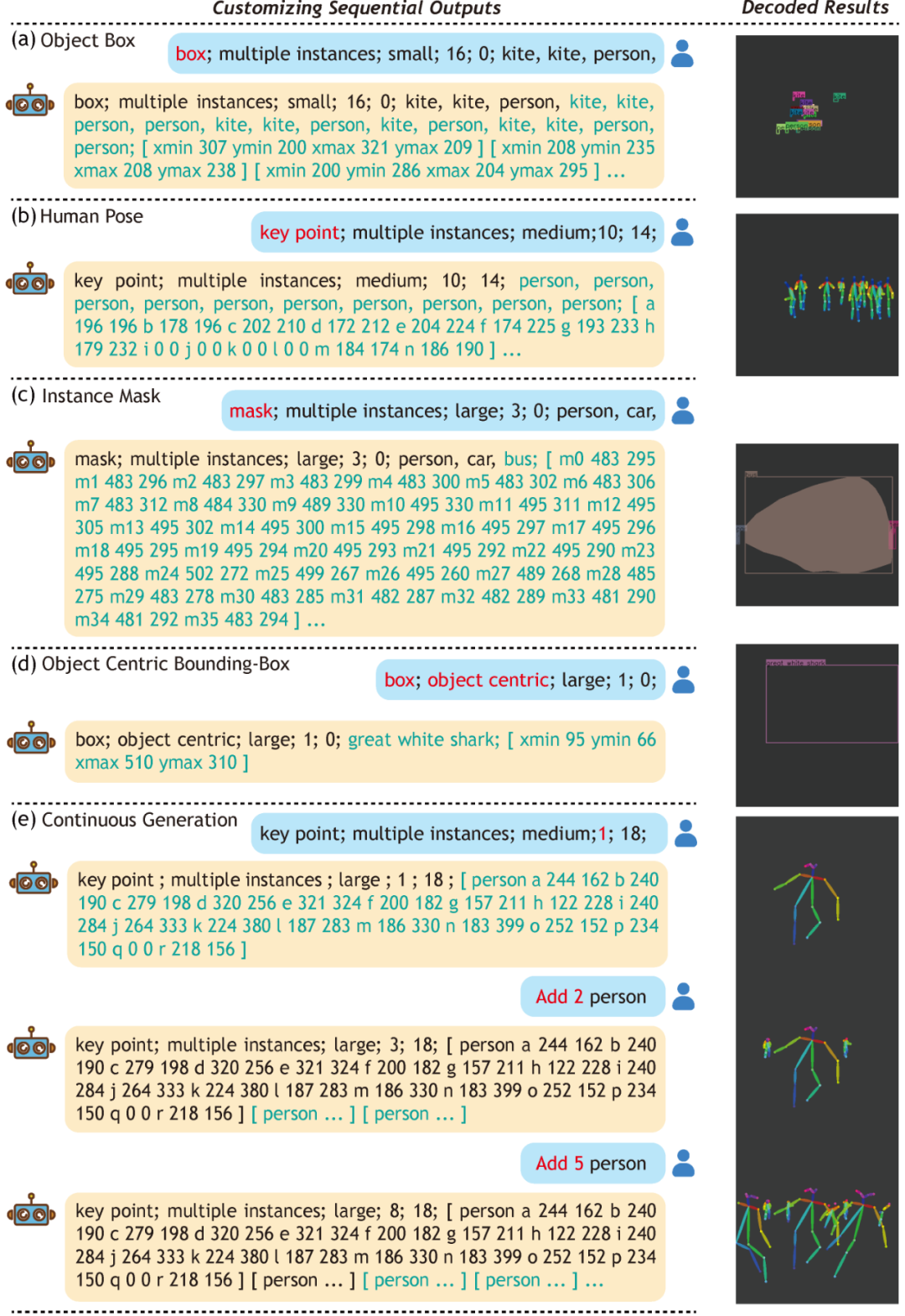
圖1 定制序列輸出
效果展示



-
模型
+關注
關注
1文章
3313瀏覽量
49233 -
數據集
+關注
關注
4文章
1209瀏覽量
24836 -
圖像生成
+關注
關注
0文章
22瀏覽量
6903
原文標題:NeurIPS 2023 | NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
宏集X7 & X10系列手持HMI——突破限制,賦能工業現場

如何判斷產品需不需要做AT&amp;amp;T認證?AT&amp;amp;T測試內容和要求分享

北美運營商AT&amp;amp;T認證中的VoLTE測試項
能力再次提升! 迅為RK3588/RK3568開發板&amp;amp;核心板新增定制分區鏡像

視覺傳感器 | 這些常見的Q&amp;amp;A!今天統一回答!


北美運營商AT&amp;amp;T認證的費用受哪些因素影響

onsemi LV/MV MOSFET 產品介紹 &amp;amp; 行業應用

FS201資料(pcb &amp; DEMO &amp; 原理圖)
北美運營商AT&amp;amp;T認證入庫產品范圍名單相關
解讀北美運營商,AT&amp;amp;T的認證分類與認證內容分享
在TSMaster中加載基于DotNet平臺的Seed&amp;amp;Key







 工商網監
工商網監
評論